 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Adaptive State Aggregation Algorithm for Markov Decision Processes
Paper and Code
Jul 23, 2021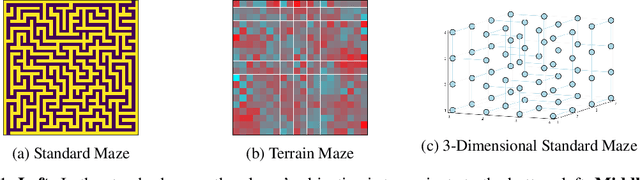
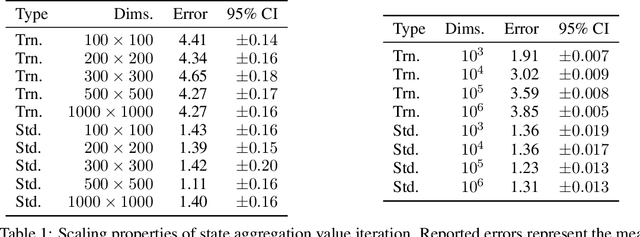
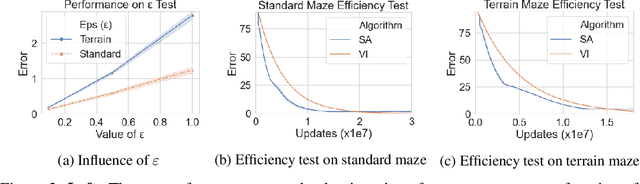
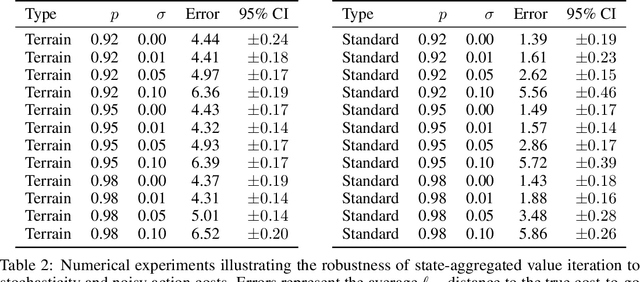
Value iteration is a well-known method of solving Markov Decision Processes (MDPs) that is simple to implement and boasts strong theoretical convergence guarantees. However, the computational cost of value iteration quickly becomes infeasible as the size of the state space increases. Various methods have been proposed to overcome this issue for value iteration in large state and action space MDPs, often at the price, however, of generalizability and algorithmic simplicity. In this paper, we propose an intuitive algorithm for solving MDPs that reduces the cost of value iteration updates by dynamically grouping together states with similar cost-to-go values. We also prove that our algorithm converges almost surely to within \(2\varepsilon / (1 - \gamma)\) of the true optimal value in the \(\ell^\infty\) norm, where \(\gamma\) is the discount factor and aggregated states differ by at most \(\varepsilon\). Numerical experiments on a variety of simulated environments confirm the robustness of our algorithm and its ability to solve MDPs with much cheaper updates especially as the scale of the MDP problem increases.