 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompound Figure Separation of Biomedical Images with Side Loss
Paper and Code
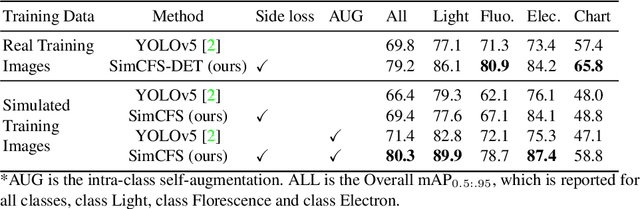
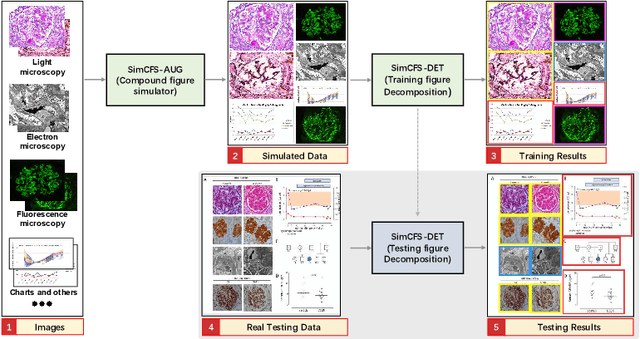
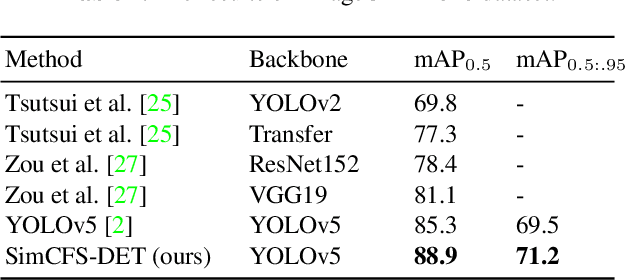
Unsupervised learning algorithms (e.g., self-supervised learning, auto-encoder, contrastive learning) allow deep learning models to learn effective image representations from large-scale unlabeled data. In medical image analysis, even unannotated data can be difficult to obtain for individual labs. Fortunately, national-level efforts have been made to provide efficient access to obtain biomedical image data from previous scientific publications. For instance, NIH has launched the Open-i search engine that provides a large-scale image database with free access. However, the images in scientific publications consist of a considerable amount of compound figures with subplots. To extract and curate individual subplots, many different compound figure separation approaches have been developed, especially with the recent advances in deep learning. However, previous approaches typically required resource extensive bounding box annotation to train detection models. In this paper, we propose a simple compound figure separation (SimCFS) framework that uses weak classification annotations from individual images. Our technical contribution is three-fold: (1) we introduce a new side loss that is designed for compound figure separation; (2) we introduce an intra-class image augmentation method to simulate hard cases; (3) the proposed framework enables an efficient deployment to new classes of images, without requiring resource extensive bounding box annotations. From the results, the SimCFS achieved a new state-of-the-art performance on the ImageCLEF 2016 Compound Figure Separation Database. The source code of SimCFS is made publicly available at https://github.com/hrlblab/ImageSeperation.