 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocally Enhanced Self-Attention: Rethinking Self-Attention as Local and Context Terms
Paper and Code
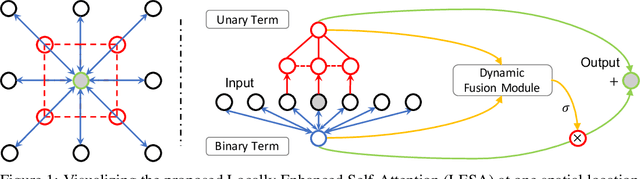

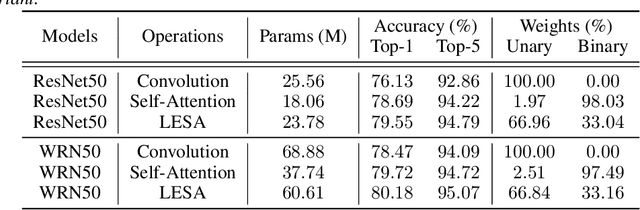

Self-Attention has become prevalent in computer vision models. Inspired by fully connected Conditional Random Fields (CRFs), we decompose it into local and context terms. They correspond to the unary and binary terms in CRF and are implemented by attention mechanisms with projection matrices. We observe that the unary terms only make small contributions to the outputs, and meanwhile standard CNNs that rely solely on the unary terms achieve great performances on a variety of tasks. Therefore, we propose Locally Enhanced Self-Attention (LESA), which enhances the unary term by incorporating it with convolutions, and utilizes a fusion module to dynamically couple the unary and binary operations. In our experiments, we replace the self-attention modules with LESA. The results on ImageNet and COCO show the superiority of LESA over convolution and self-attention baselines for the tasks of image recognition, object detection, and instance segmentation. The code is made publicly available.