 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind Your Outliers! Investigating the Negative Impact of Outliers on Active Learning for Visual Question Answering
Paper and Code
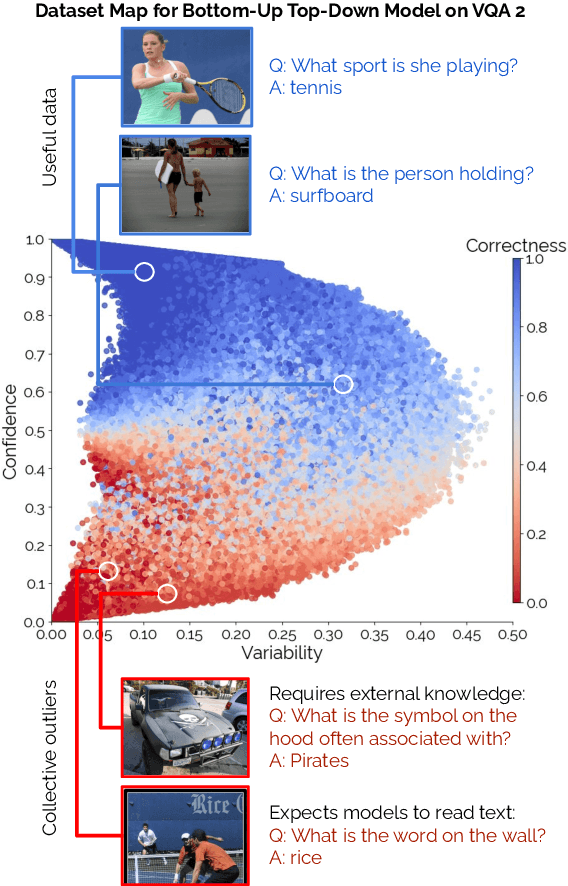
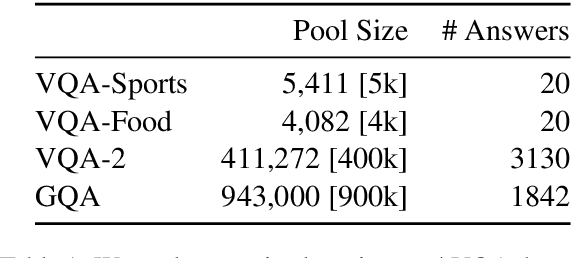
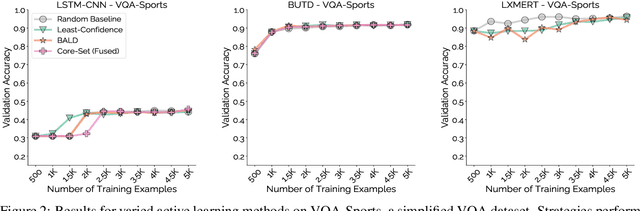
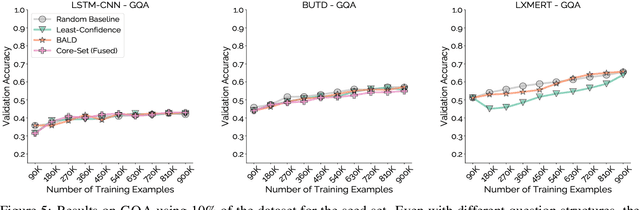
Active learning promises to alleviate the massive data needs of supervised machine learning: it has successfully improved sample efficiency by an order of magnitude on traditional tasks like topic classification and object recognition. However, we uncover a striking contrast to this promise: across 5 models and 4 datasets on the task of visual question answering, a wide variety of active learning approaches fail to outperform random selection. To understand this discrepancy, we profile 8 active learning methods on a per-example basis, and identify the problem as collective outliers -- groups of examples that active learning methods prefer to acquire but models fail to learn (e.g., questions that ask about text in images or require external knowledge). Through systematic ablation experiments and qualitative visualizations, we verify that collective outliers are a general phenomenon responsible for degrading pool-based active learning. Notably, we show that active learning sample efficiency increases significantly as the number of collective outliers in the active learning pool decreases. We conclude with a discussion and prescriptive recommendations for mitigating the effects of these outliers in future work.