 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplicit Clothing Modeling for an Animatable Full-Body Avatar
Paper and Code
Jun 30, 2021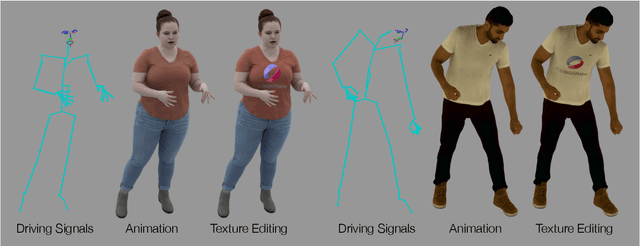
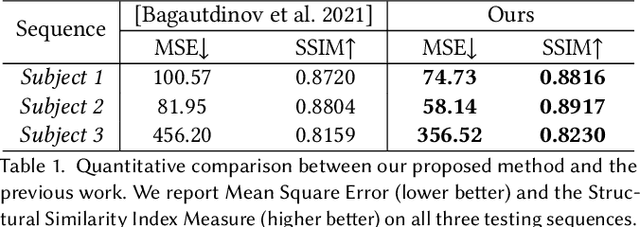

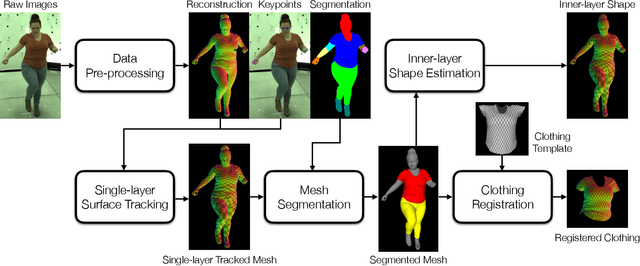
Recent work has shown great progress in building photorealistic animatable full-body codec avatars, but these avatars still face difficulties in generating high-fidelity animation of clothing. To address the difficulties, we propose a method to build an animatable clothed body avatar with an explicit representation of the clothing on the upper body from multi-view captured videos. We use a two-layer mesh representation to separately register the 3D scans with templates. In order to improve the photometric correspondence across different frames, texture alignment is then performed through inverse rendering of the clothing geometry and texture predicted by a variational autoencoder. We then train a new two-layer codec avatar with separate modeling of the upper clothing and the inner body layer. To learn the interaction between the body dynamics and clothing states, we use a temporal convolution network to predict the clothing latent code based on a sequence of input skeletal poses. We show photorealistic animation output for three different actors, and demonstrate the advantage of our clothed-body avatars over single-layer avatars in the previous work. We also show the benefit of an explicit clothing model which allows the clothing texture to be edited in the animation output.