 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoAdapt: Automated Segmentation Network Search for Unsupervised Domain Adaptation
Paper and Code
Jun 24, 2021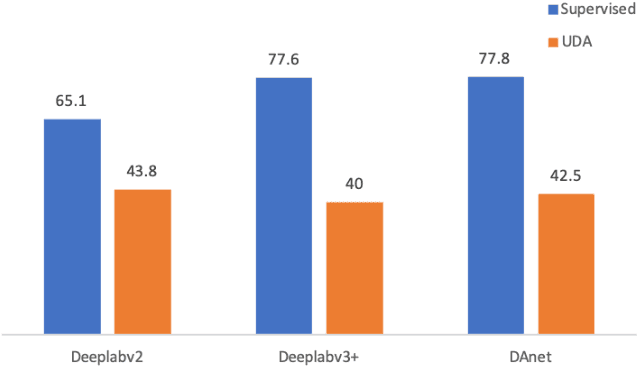
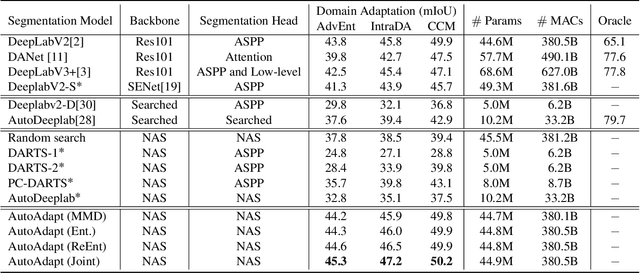
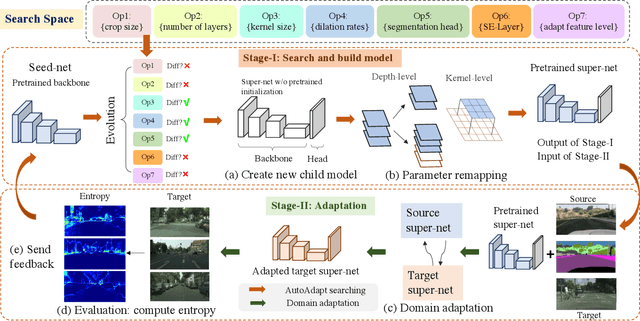
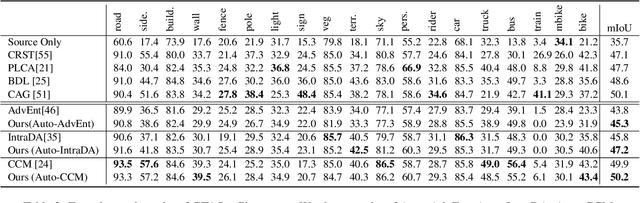
Neural network-based semantic segmentation has achieved remarkable results when large amounts of annotated data are available, that is, in the supervised case. However, such data is expensive to collect and so methods have been developed to adapt models trained on related, often synthetic data for which labels are readily available. Current adaptation approaches do not consider the dependence of the generalization/transferability of these models on network architecture. In this paper, we perform neural architecture search (NAS) to provide architecture-level perspective and analysis for domain adaptation. We identify the optimization gap that exists when searching architectures for unsupervised domain adaptation which makes this NAS problem uniquely difficult. We propose bridging this gap by using maximum mean discrepancy and regional weighted entropy to estimate the accuracy metric. Experimental results on several widely adopted benchmarks show that our proposed AutoAdapt framework indeed discovers architectures that improve the performance of a number of existing adaptation techniques.