 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxelEmbed: 3D Instance Segmentation and Tracking with Voxel Embedding based Deep Learning
Paper and Code
Jun 22, 2021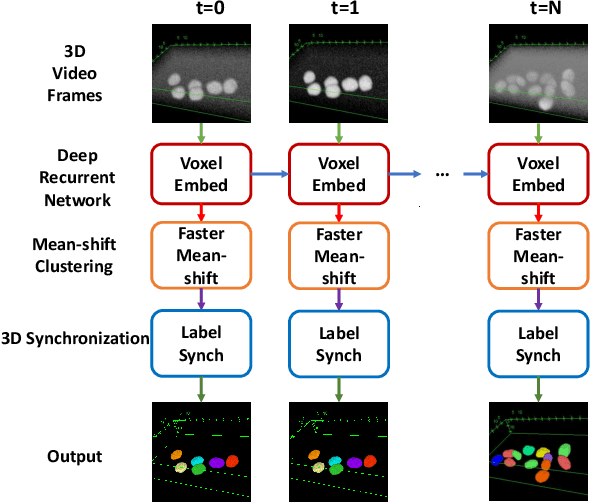
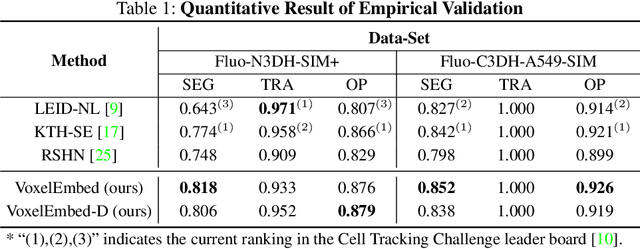
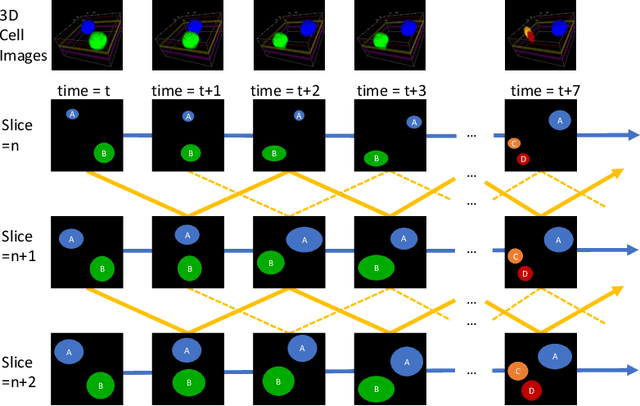
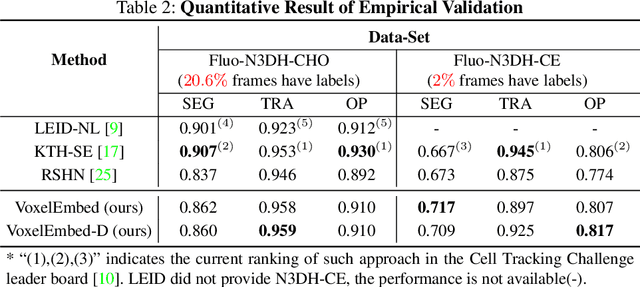
Recent advances in bioimaging have provided scientists a superior high spatial-temporal resolution to observe dynamics of living cells as 3D volumetric videos. Unfortunately, the 3D biomedical video analysis is lagging, impeded by resource insensitive human curation using off-the-shelf 3D analytic tools. Herein, biologists often need to discard a considerable amount of rich 3D spatial information by compromising on 2D analysis via maximum intensity projection. Recently, pixel embedding-based cell instance segmentation and tracking provided a neat and generalizable computing paradigm for understanding cellular dynamics. In this work, we propose a novel spatial-temporal voxel-embedding (VoxelEmbed) based learning method to perform simultaneous cell instance segmenting and tracking on 3D volumetric video sequences. Our contribution is in four-fold: (1) The proposed voxel embedding generalizes the pixel embedding with 3D context information; (2) Present a simple multi-stream learning approach that allows effective spatial-temporal embedding; (3) Accomplished an end-to-end framework for one-stage 3D cell instance segmentation and tracking without heavy parameter tuning; (4) The proposed 3D quantification is memory efficient via a single GPU with 12 GB memory. We evaluate our VoxelEmbed method on four 3D datasets (with different cell types) from the ISBI Cell Tracking Challenge. The proposed VoxelEmbed method achieved consistent superior overall performance (OP) on two densely annotated datasets. The performance is also competitive on two sparsely annotated cohorts with 20.6% and 2% of data-set having segmentation annotations. The results demonstrate that the VoxelEmbed method is a generalizable and memory-efficient solution.