 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Autoregressive Transformer for Image Captioning
Paper and Code
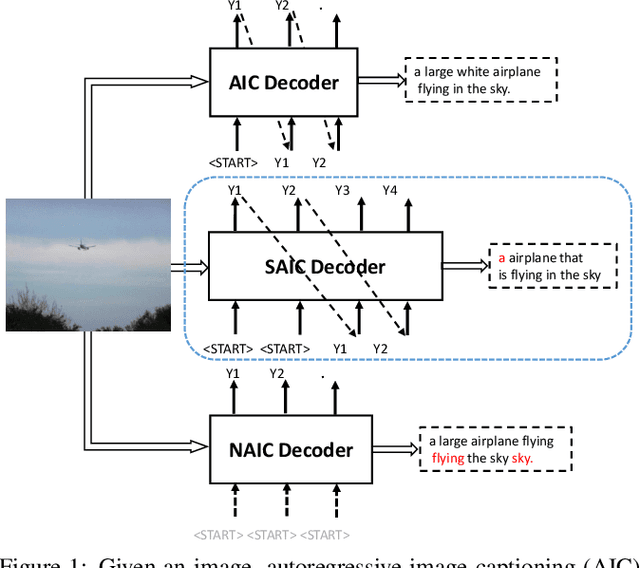
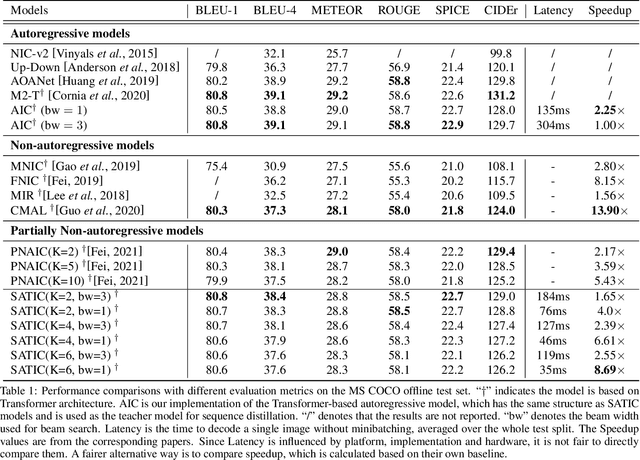
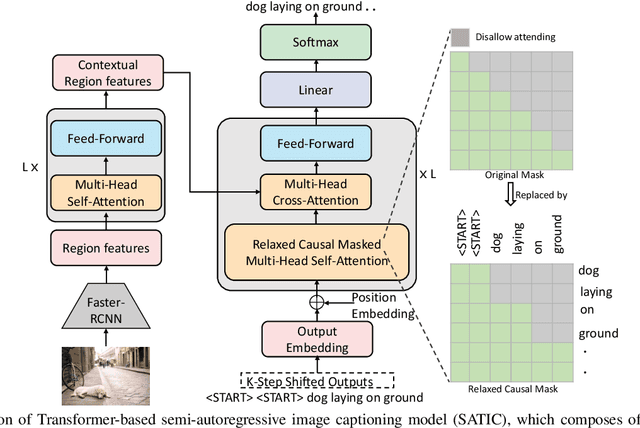
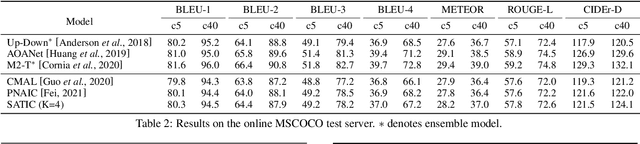
Current state-of-the-art image captioning models adopt autoregressive decoders, \ie they generate each word by conditioning on previously generated words, which leads to heavy latency during inference. To tackle this issue, non-autoregressive image captioning models have recently been proposed to significantly accelerate the speed of inference by generating all words in parallel. However, these non-autoregressive models inevitably suffer from large generation quality degradation since they remove words dependence excessively. To make a better trade-off between speed and quality, we introduce a semi-autoregressive model for image captioning~(dubbed as SATIC), which keeps the autoregressive property in global but generates words parallelly in local. Based on Transformer, there are only a few modifications needed to implement SATIC. Extensive experiments on the MSCOCO image captioning benchmark show that SATIC can achieve a better trade-off without bells and whistles. Code is available at {\color{magenta}\url{https://github.com/YuanEZhou/satic}}.