 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThompson Sampling for Unimodal Bandits
Paper and Code
Jun 16, 2021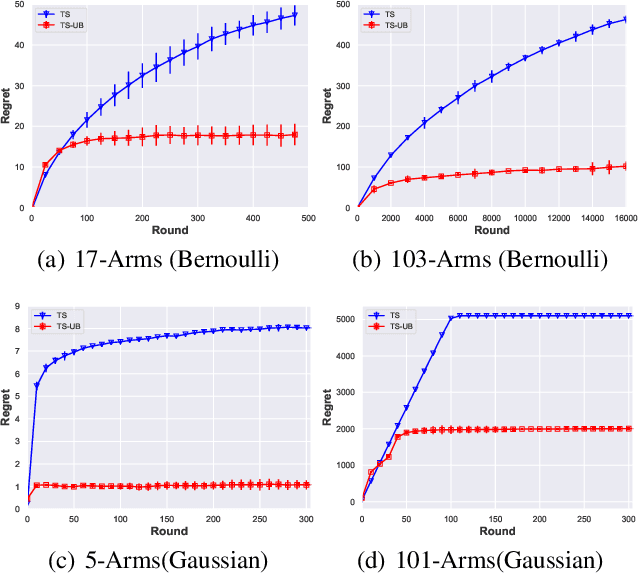
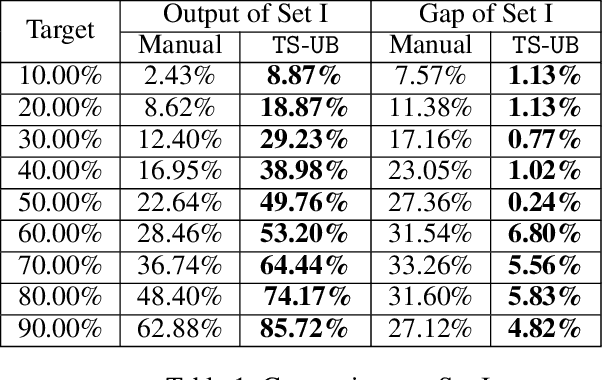
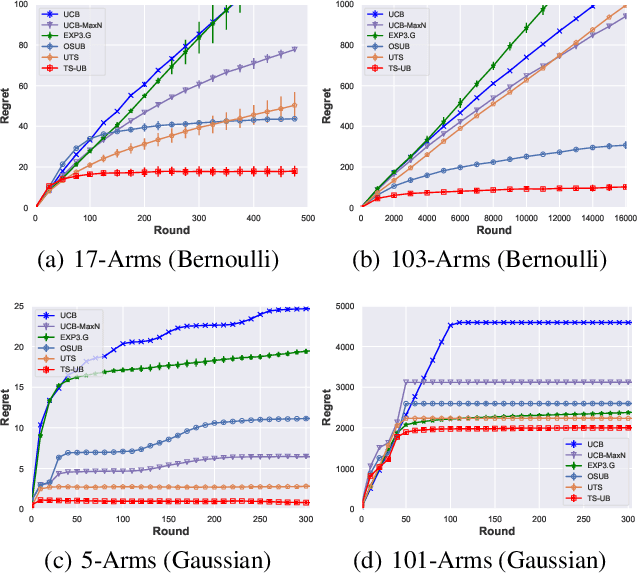
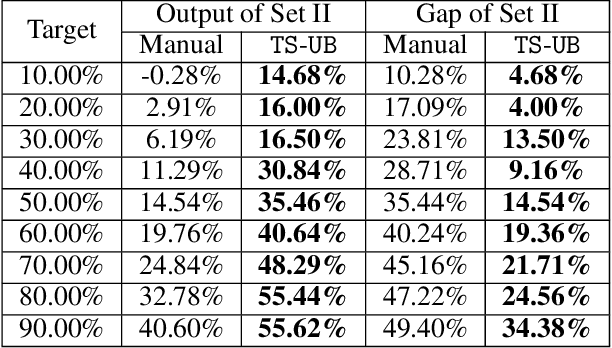
In this paper, we propose a Thompson Sampling algorithm for \emph{unimodal} bandits, where the expected reward is unimodal over the partially ordered arms. To exploit the unimodal structure better, at each step, instead of exploration from the entire decision space, our algorithm makes decision according to posterior distribution only in the neighborhood of the arm that has the highest empirical mean estimate. We theoretically prove that, for Bernoulli rewards, the regret of our algorithm reaches the lower bound of unimodal bandits, thus it is asymptotically optimal. For Gaussian rewards, the regret of our algorithm is $\mathcal{O}(\log T)$, which is far better than standard Thompson Sampling algorithms. Extensive experiments demonstrate the effectiveness of the proposed algorithm on both synthetic data sets and the real-world applications.