 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking InfoNCE: How Many Negative Samples Do You Need?
Paper and Code
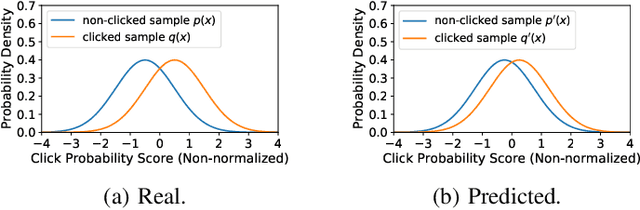
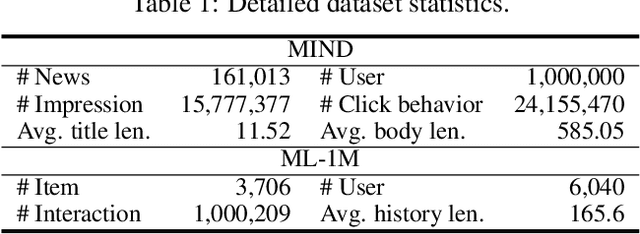
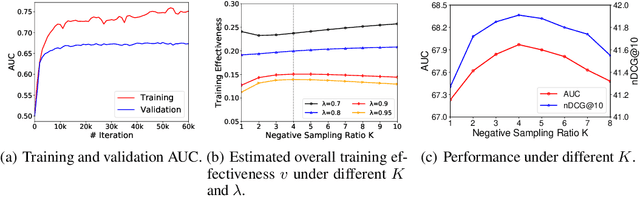
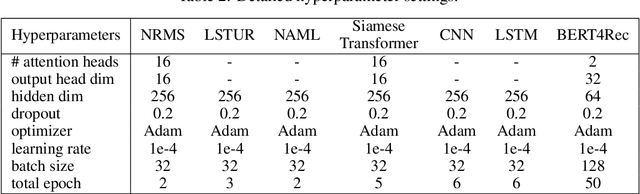
InfoNCE loss is a widely used loss function for contrastive model training. It aims to estimate the mutual information between a pair of variables by discriminating between each positive pair and its associated $K$ negative pairs. It is proved that when the sample labels are clean, the lower bound of mutual information estimation is tighter when more negative samples are incorporated, which usually yields better model performance. However, in many real-world tasks the labels often contain noise, and incorporating too many noisy negative samples for model training may be suboptimal. In this paper, we study how many negative samples are optimal for InfoNCE in different scenarios via a semi-quantitative theoretical framework. More specifically, we first propose a probabilistic model to analyze the influence of the negative sampling ratio $K$ on training sample informativeness. Then, we design a training effectiveness function to measure the overall influence of training samples on model learning based on their informativeness. We estimate the optimal negative sampling ratio using the $K$ value that maximizes the training effectiveness function. Based on our framework, we further propose an adaptive negative sampling method that can dynamically adjust the negative sampling ratio to improve InfoNCE based model training. Extensive experiments on different real-world datasets show our framework can accurately predict the optimal negative sampling ratio in different tasks, and our proposed adaptive negative sampling method can achieve better performance than the commonly used fixed negative sampling ratio strategy.