 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Visual Place Recognition in Dynamics-Invariant Perception Space
Paper and Code
May 17, 2021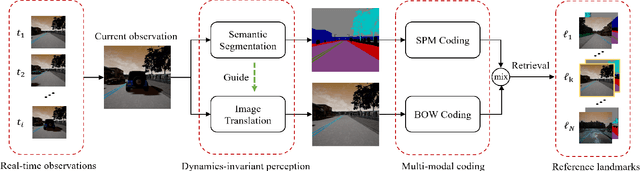
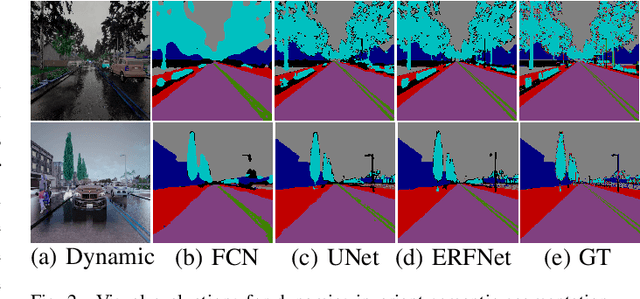

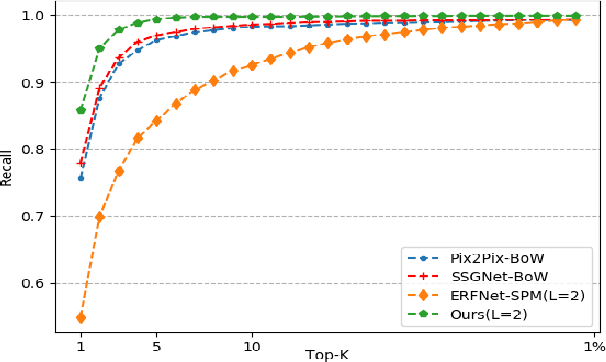
Visual place recognition is one of the essential and challenging problems in the fields of robotics. In this letter, we for the first time explore the use of multi-modal fusion of semantic and visual modalities in dynamics-invariant space to improve place recognition in dynamic environments. We achieve this by first designing a novel deep learning architecture to generate the static semantic segmentation and recover the static image directly from the corresponding dynamic image. We then innovatively leverage the spatial-pyramid-matching model to encode the static semantic segmentation into feature vectors. In parallel, the static image is encoded using the popular Bag-of-words model. On the basis of the above multi-modal features, we finally measure the similarity between the query image and target landmark by the joint similarity of their semantic and visual codes. Extensive experiments demonstrate the effectiveness and robustness of the proposed approach for place recognition in dynamic environments.