 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Non-uniformity in First-order Non-convex Optimization
Paper and Code
May 13, 2021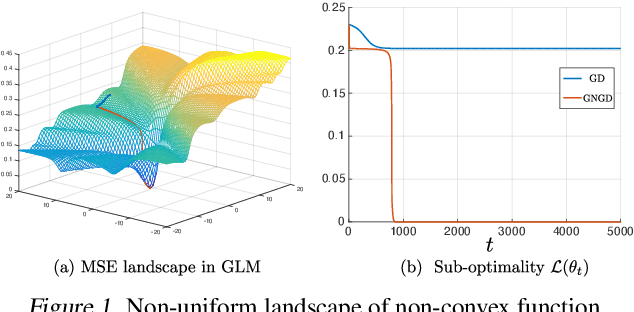
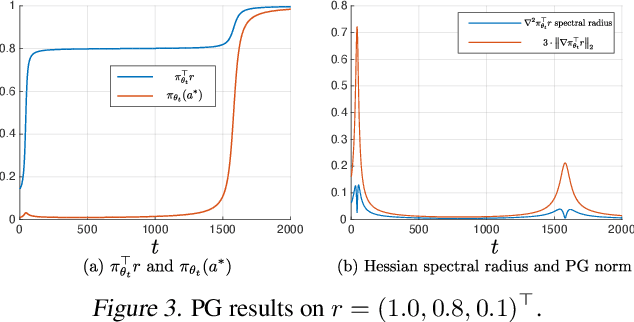
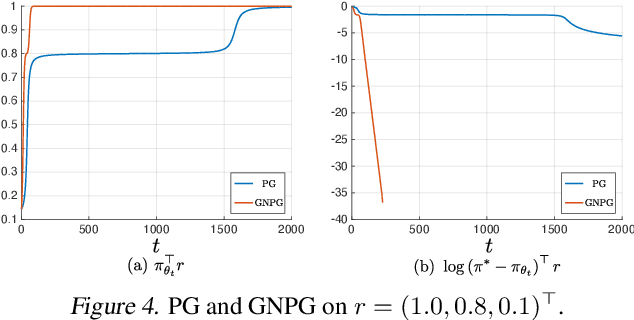
Classical global convergence results for first-order methods rely on uniform smoothness and the \L{}ojasiewicz inequality. Motivated by properties of objective functions that arise in machine learning, we propose a non-uniform refinement of these notions, leading to \emph{Non-uniform Smoothness} (NS) and \emph{Non-uniform \L{}ojasiewicz inequality} (N\L{}). The new definitions inspire new geometry-aware first-order methods that are able to converge to global optimality faster than the classical $\Omega(1/t^2)$ lower bounds. To illustrate the power of these geometry-aware methods and their corresponding non-uniform analysis, we consider two important problems in machine learning: policy gradient optimization in reinforcement learning (PG), and generalized linear model training in supervised learning (GLM). For PG, we find that normalizing the gradient ascent method can accelerate convergence to $O(e^{-t})$ while incurring less overhead than existing algorithms. For GLM, we show that geometry-aware normalized gradient descent can also achieve a linear convergence rate, which significantly improves the best known results. We additionally show that the proposed geometry-aware descent methods escape landscape plateaus faster than standard gradient descent. Experimental results are used to illustrate and complement the theoretical findings.