 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextOCR: Towards large-scale end-to-end reasoning for arbitrary-shaped scene text
Paper and Code
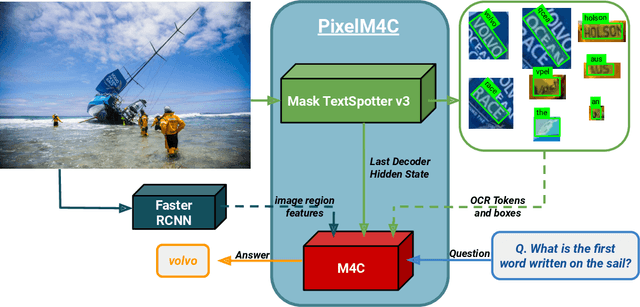
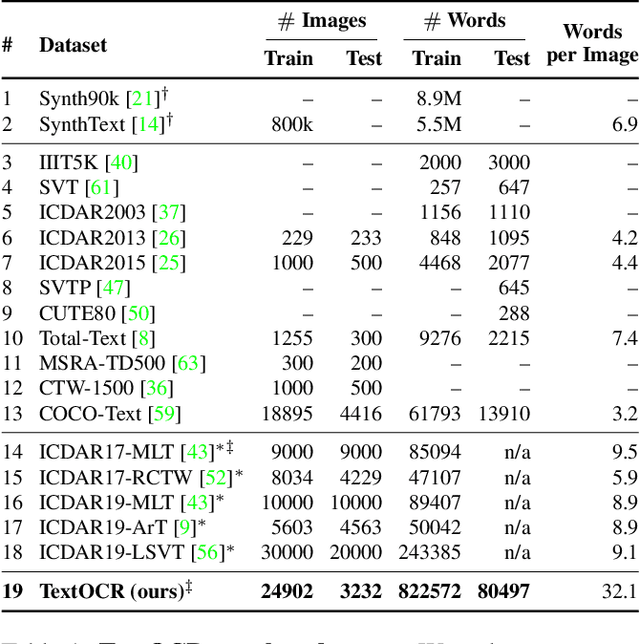

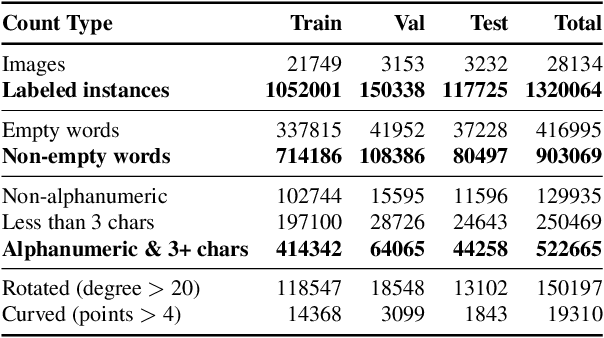
A crucial component for the scene text based reasoning required for TextVQA and TextCaps datasets involve detecting and recognizing text present in the images using an optical character recognition (OCR) system. The current systems are crippled by the unavailability of ground truth text annotations for these datasets as well as lack of scene text detection and recognition datasets on real images disallowing the progress in the field of OCR and evaluation of scene text based reasoning in isolation from OCR systems. In this work, we propose TextOCR, an arbitrary-shaped scene text detection and recognition with 900k annotated words collected on real images from TextVQA dataset. We show that current state-of-the-art text-recognition (OCR) models fail to perform well on TextOCR and that training on TextOCR helps achieve state-of-the-art performance on multiple other OCR datasets as well. We use a TextOCR trained OCR model to create PixelM4C model which can do scene text based reasoning on an image in an end-to-end fashion, allowing us to revisit several design choices to achieve new state-of-the-art performance on TextVQA dataset.