 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatching Visual Features to Hierarchical Semantic Topics for Image Paragraph Captioning
Paper and Code
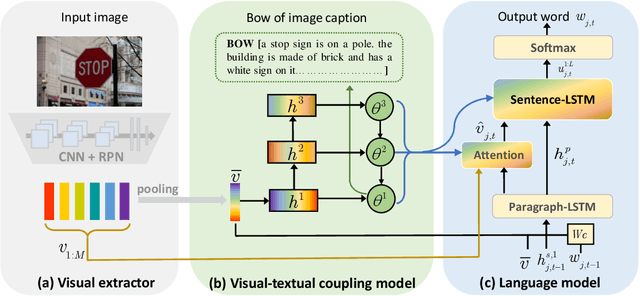
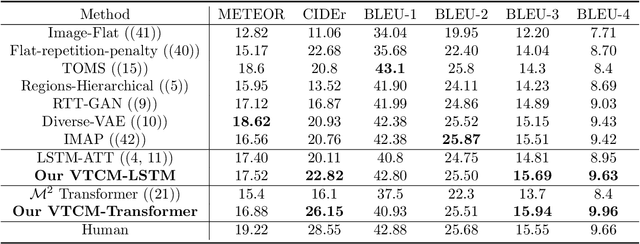
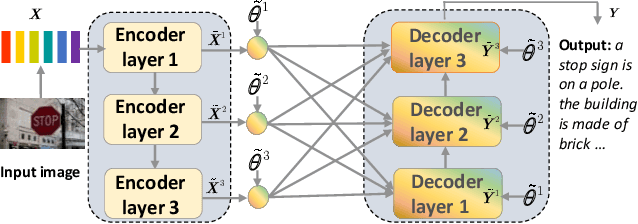
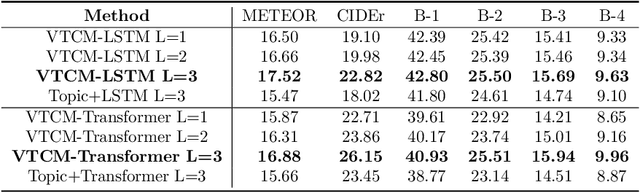
Observing a set of images and their corresponding paragraph-captions, a challenging task is to learn how to produce a semantically coherent paragraph to describe the visual content of an image. Inspired by recent successes in integrating semantic topics into this task, this paper develops a plug-and-play hierarchical-topic-guided image paragraph generation framework, which couples a visual extractor with a deep topic model to guide the learning of a language model. To capture the correlations between the image and text at multiple levels of abstraction and learn the semantic topics from images, we design a variational inference network to build the mapping from image features to textual captions. To guide the paragraph generation, the learned hierarchical topics and visual features are integrated into the language model, including Long Short-Term Memory (LSTM) and Transformer, and jointly optimized. Experiments on public dataset demonstrate that the proposed models, which are competitive with many state-of-the-art approaches in terms of standard evaluation metrics, can be used to both distill interpretable multi-layer topics and generate diverse and coherent captions.