 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEARL: Parallelized Expert-Assisted Reinforcement Learning for Scene Rearrangement Planning
Paper and Code
May 10, 2021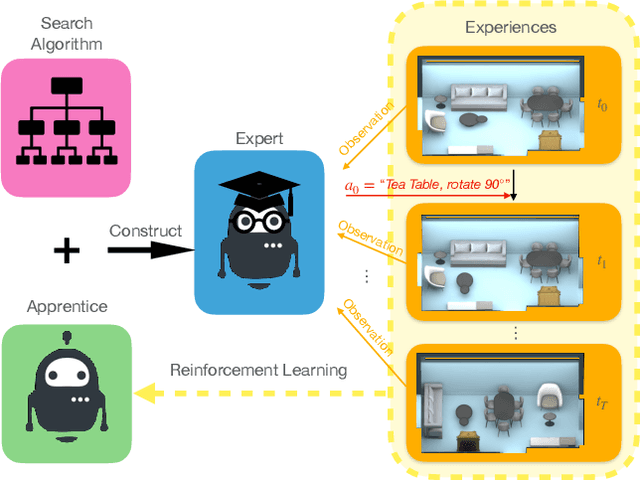

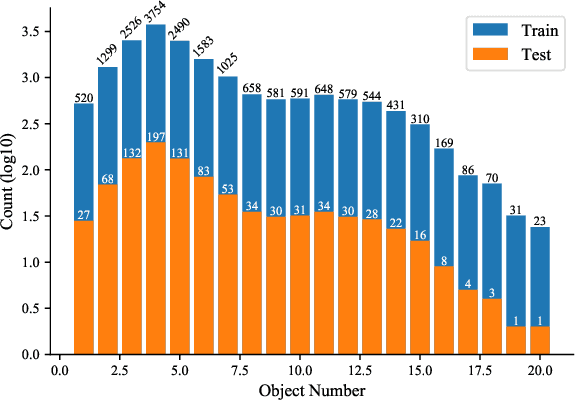
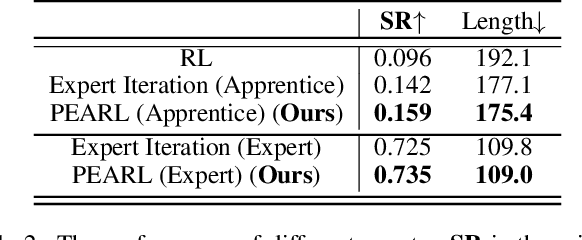
Scene Rearrangement Planning (SRP) is an interior task proposed recently. The previous work defines the action space of this task with handcrafted coarse-grained actions that are inflexible to be used for transforming scene arrangement and intractable to be deployed in practice. Additionally, this new task lacks realistic indoor scene rearrangement data to feed popular data-hungry learning approaches and meet the needs of quantitative evaluation. To address these problems, we propose a fine-grained action definition for SRP and introduce a large-scale scene rearrangement dataset. We also propose a novel learning paradigm to efficiently train an agent through self-playing, without any prior knowledge. The agent trained via our paradigm achieves superior performance on the introduced dataset compared to the baseline agents. We provide a detailed analysis of the design of our approach in our experiments.