 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMS MARCO: Benchmarking Ranking Models in the Large-Data Regime
Paper and Code
May 09, 2021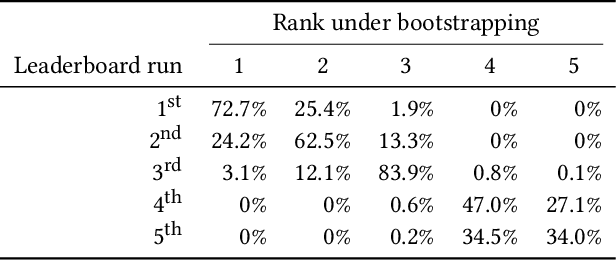
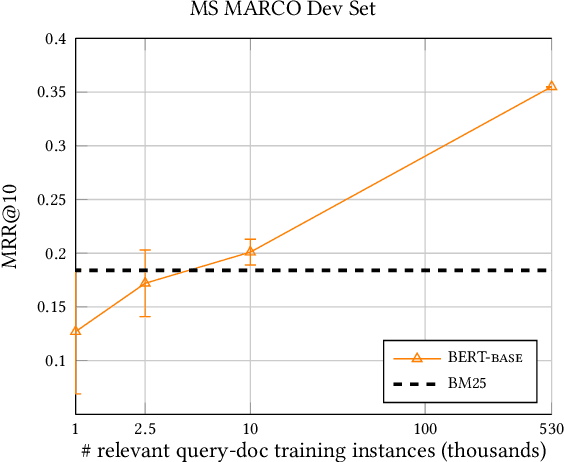
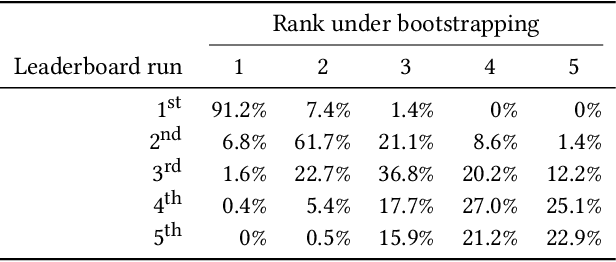
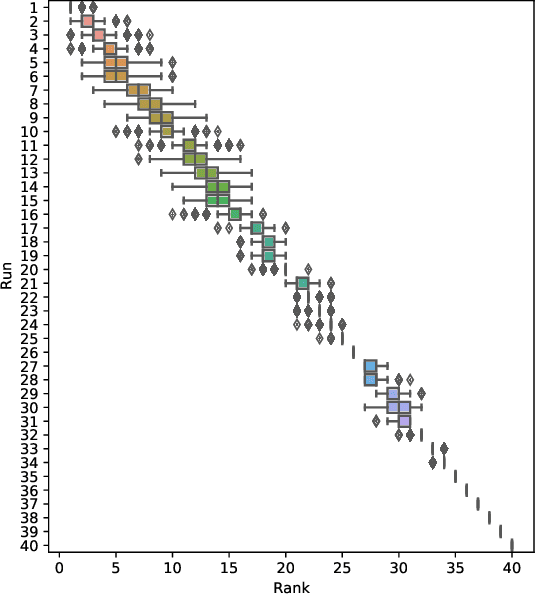
Evaluation efforts such as TREC, CLEF, NTCIR and FIRE, alongside public leaderboard such as MS MARCO, are intended to encourage research and track our progress, addressing big questions in our field. However, the goal is not simply to identify which run is "best", achieving the top score. The goal is to move the field forward by developing new robust techniques, that work in many different settings, and are adopted in research and practice. This paper uses the MS MARCO and TREC Deep Learning Track as our case study, comparing it to the case of TREC ad hoc ranking in the 1990s. We show how the design of the evaluation effort can encourage or discourage certain outcomes, and raising questions about internal and external validity of results. We provide some analysis of certain pitfalls, and a statement of best practices for avoiding such pitfalls. We summarize the progress of the effort so far, and describe our desired end state of "robust usefulness", along with steps that might be required to get us there.