 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLawformer: A Pre-trained Language Model for Chinese Legal Long Documents
Paper and Code
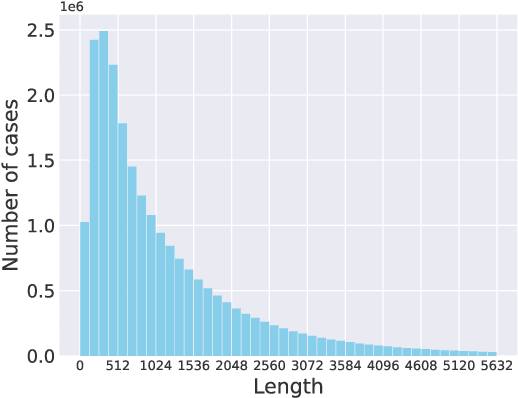
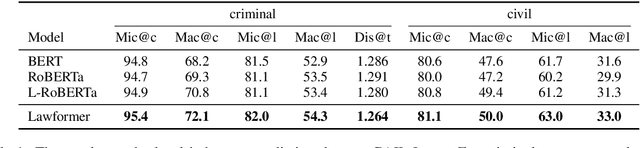
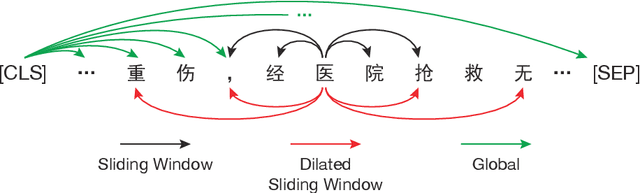

Legal artificial intelligence (LegalAI) aims to benefit legal systems with the technology of artificial intelligence, especially natural language processing (NLP). Recently, inspired by the success of pre-trained language models (PLMs) in the generic domain, many LegalAI researchers devote their effort to apply PLMs to legal tasks. However, utilizing PLMs to address legal tasks is still challenging, as the legal documents usually consist of thousands of tokens, which is far longer than the length that mainstream PLMs can process. In this paper, we release the Longformer-based pre-trained language model, named as Lawformer, for Chinese legal long documents understanding. We evaluate Lawformer on a variety of LegalAI tasks, including judgment prediction, similar case retrieval, legal reading comprehension, and legal question answering. The experimental results demonstrate that our model can achieve promising improvement on tasks with long documents as inputs.