Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliability Testing for Natural Language Processing Systems
Paper and Code
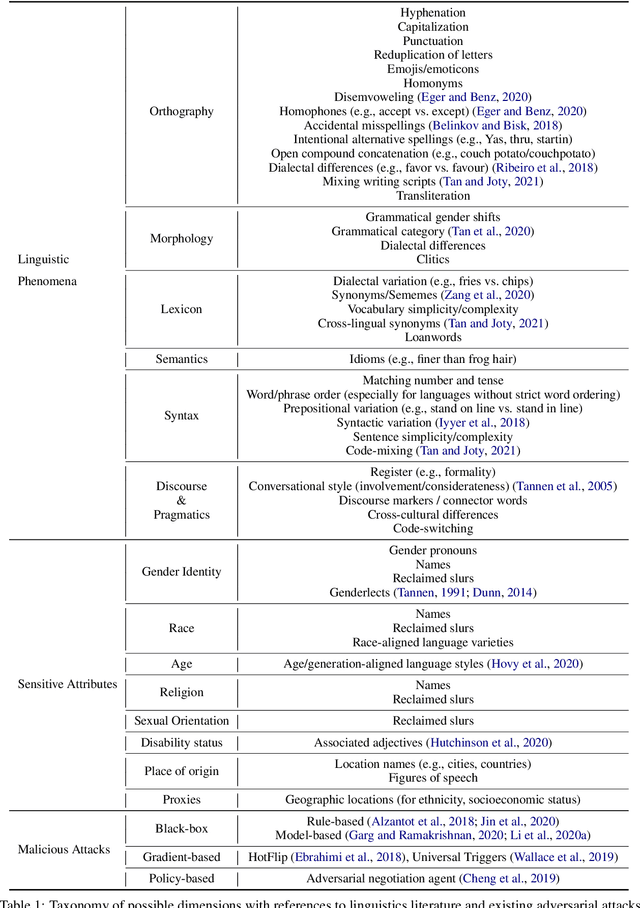
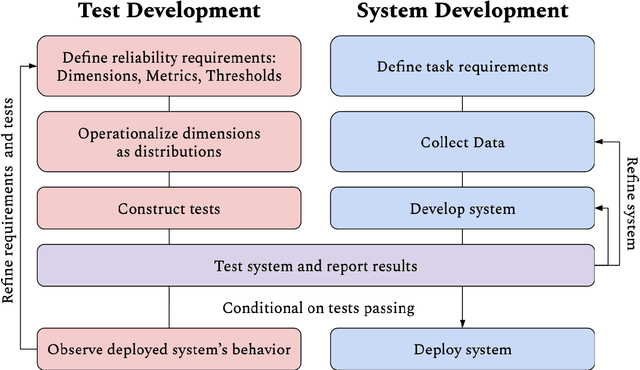
Questions of fairness, robustness, and transparency are paramount to address before deploying NLP systems. Central to these concerns is the question of reliability: Can NLP systems reliably treat different demographics fairly and function correctly in diverse and noisy environments? To address this, we argue for the need for reliability testing and contextualize it among existing work on improving accountability. We show how adversarial attacks can be reframed for this goal, via a framework for developing reliability tests. We argue that reliability testing -- with an emphasis on interdisciplinary collaboration -- will enable rigorous and targeted testing, and aid in the enactment and enforcement of industry standards.
* Accepted to ACL-IJCNLP 2021 (main conference). Camera-ready version
View paper on