 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRATT: Leveraging Unlabeled Data to Guarantee Generalization
Paper and Code
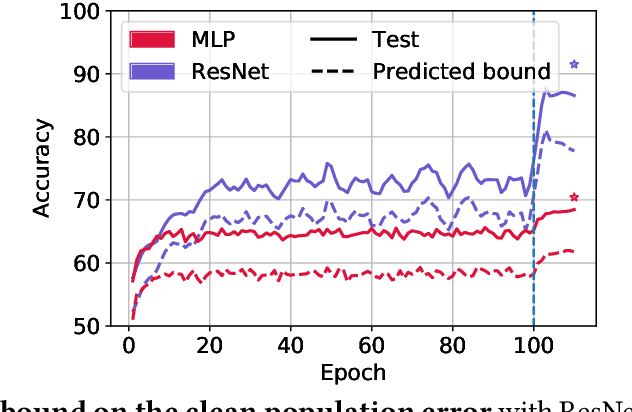
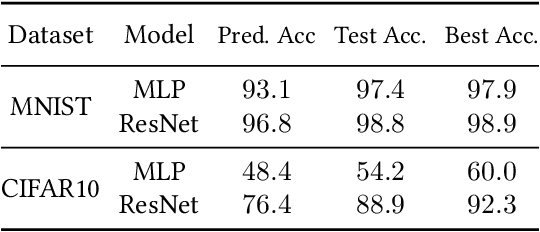
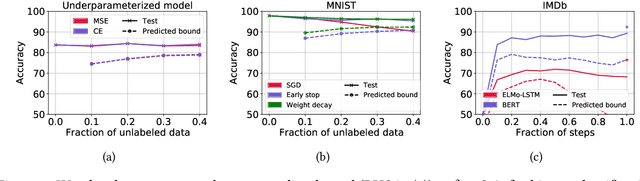
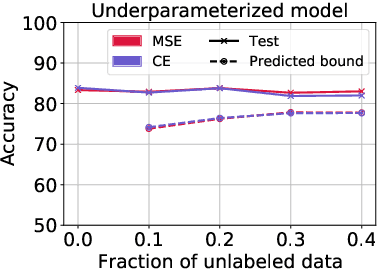
To assess generalization, machine learning scientists typically either (i) bound the generalization gap and then (after training) plug in the empirical risk to obtain a bound on the true risk; or (ii) validate empirically on holdout data. However, (i) typically yields vacuous guarantees for overparameterized models. Furthermore, (ii) shrinks the training set and its guarantee erodes with each re-use of the holdout set. In this paper, we introduce a method that leverages unlabeled data to produce generalization bounds. After augmenting our (labeled) training set with randomly labeled fresh examples, we train in the standard fashion. Whenever classifiers achieve low error on clean data and high error on noisy data, our bound provides a tight upper bound on the true risk. We prove that our bound is valid for 0-1 empirical risk minimization and with linear classifiers trained by gradient descent. Our approach is especially useful in conjunction with deep learning due to the early learning phenomenon whereby networks fit true labels before noisy labels but requires one intuitive assumption. Empirically, on canonical computer vision and NLP tasks, our bound provides non-vacuous generalization guarantees that track actual performance closely. This work provides practitioners with an option for certifying the generalization of deep nets even when unseen labeled data is unavailable and provides theoretical insights into the relationship between random label noise and generalization.