 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplex Neural Spatial Filter: Enhancing Multi-channel Target Speech Separation in Complex Domain
Paper and Code
Apr 26, 2021
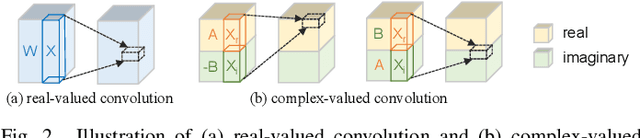
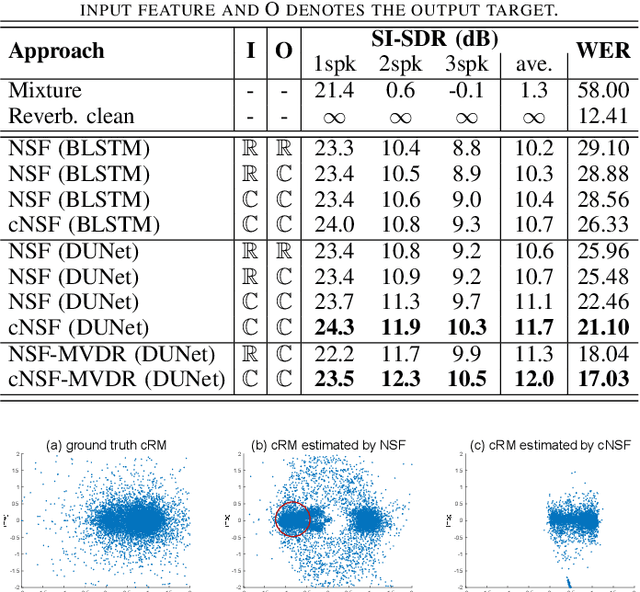
To date, mainstream target speech separation (TSS) approaches are formulated to estimate the complex ratio mask (cRM) of the target speech in time-frequency domain under supervised deep learning framework. However, the existing deep models for estimating cRM are designed in the way that the real and imaginary parts of the cRM are separately modeled using real-valued training data pairs. The research motivation of this study is to design a deep model that fully exploits the temporal-spectral-spatial information of multi-channel signals for estimating cRM directly and efficiently in complex domain. As a result, a novel TSS network is designed consisting of two modules, a complex neural spatial filter (cNSF) and an MVDR. Essentially, cNSF is a cRM estimation model and an MVDR module is cascaded to the cNSF module to reduce the nonlinear speech distortions introduced by neural network. Specifically, to fit the cRM target, all input features of cNSF are reformulated into complex-valued representations following the supervised learning paradigm. Then, to achieve good hierarchical feature abstraction, a complex deep neural network (cDNN) is delicately designed with U-Net structure. Experiments conducted on simulated multi-channel speech data demonstrate the proposed cNSF outperforms the baseline NSF by 12.1% scale-invariant signal-to-distortion ratio and 33.1% word error rate.