 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocumenting the English Colossal Clean Crawled Corpus
Paper and Code

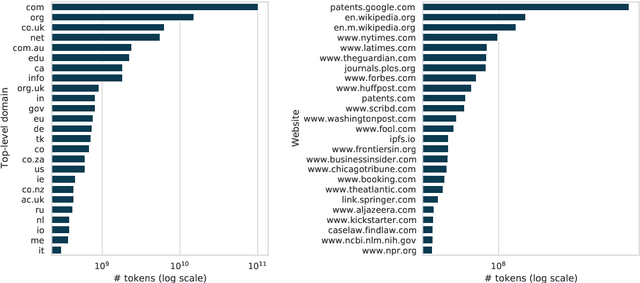
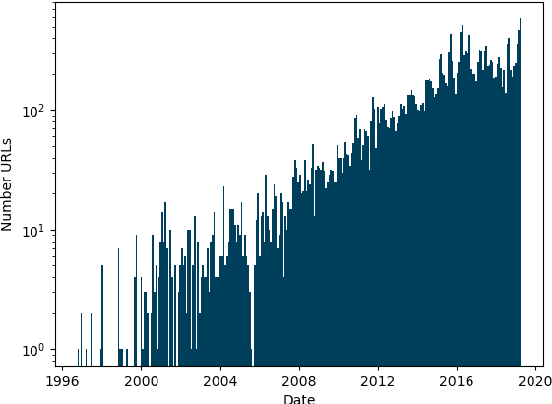
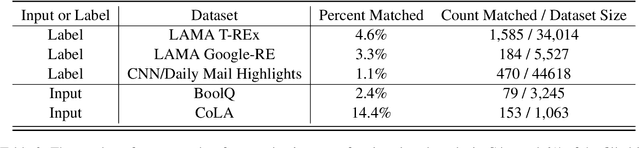
As language models are trained on ever more text, researchers are turning to some of the largest corpora available. Unlike most other types of datasets in NLP, large unlabeled text corpora are often presented with minimal documentation, and best practices for documenting them have not been established. In this work we provide the first documentation for the Colossal Clean Crawled Corpus (C4; Raffel et al., 2020), a dataset created by applying a set of filters to a single snapshot of Common Crawl. We begin with a high-level summary of the data, including distributions of where the text came from and when it was written. We then give more detailed analysis on salient parts of this data, including the most frequent sources of text (e.g., patents.google.com, which contains a significant percentage of machine translated and/or OCR'd text), the effect that the filters had on the data (they disproportionately remove text in AAE), and evidence that some other benchmark NLP dataset examples are contained in the text. We release a web interface to an interactive, indexed copy of this dataset, encouraging the community to continuously explore and report additional findings.