 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Log-Determinant Divergences for Positive Definite Matrices
Paper and Code
Apr 13, 2021
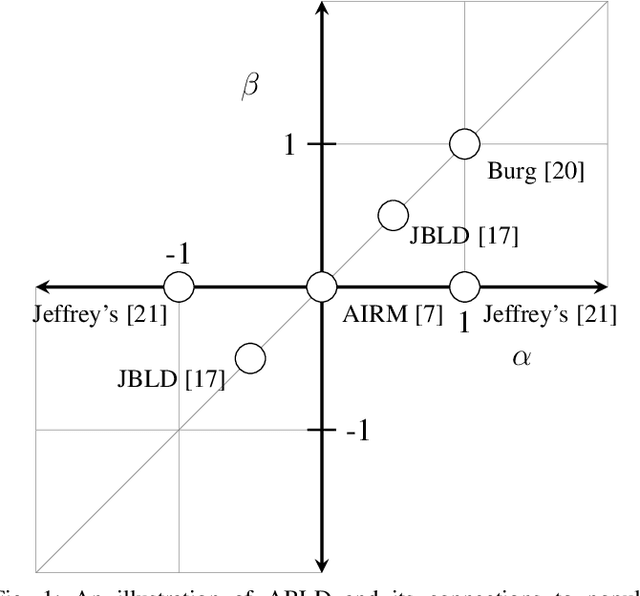

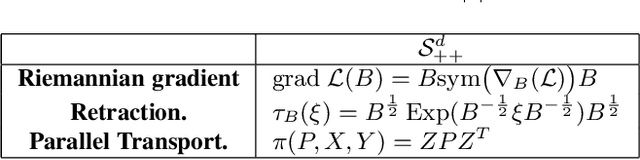
Representations in the form of Symmetric Positive Definite (SPD) matrices have been popularized in a variety of visual learning applications due to their demonstrated ability to capture rich second-order statistics of visual data. There exist several similarity measures for comparing SPD matrices with documented benefits. However, selecting an appropriate measure for a given problem remains a challenge and in most cases, is the result of a trial-and-error process. In this paper, we propose to learn similarity measures in a data-driven manner. To this end, we capitalize on the \alpha\beta-log-det divergence, which is a meta-divergence parametrized by scalars \alpha and \beta, subsuming a wide family of popular information divergences on SPD matrices for distinct and discrete values of these parameters. Our key idea is to cast these parameters in a continuum and learn them from data. We systematically extend this idea to learn vector-valued parameters, thereby increasing the expressiveness of the underlying non-linear measure. We conjoin the divergence learning problem with several standard tasks in machine learning, including supervised discriminative dictionary learning and unsupervised SPD matrix clustering. We present Riemannian gradient descent schemes for optimizing our formulations efficiently, and show the usefulness of our method on eight standard computer vision tasks.