 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual HyperNetworks for Novel Feature Adaptation
Paper and Code
Apr 12, 2021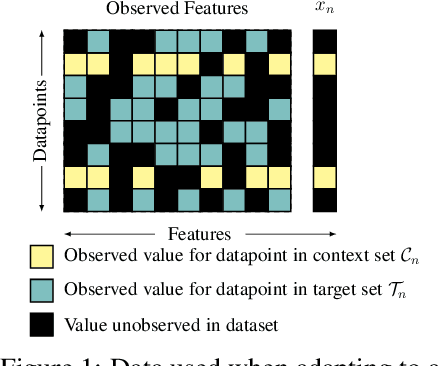
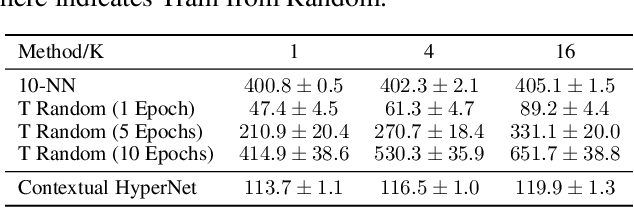
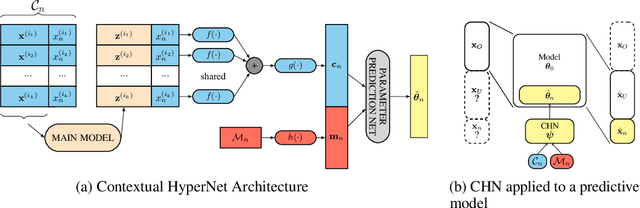
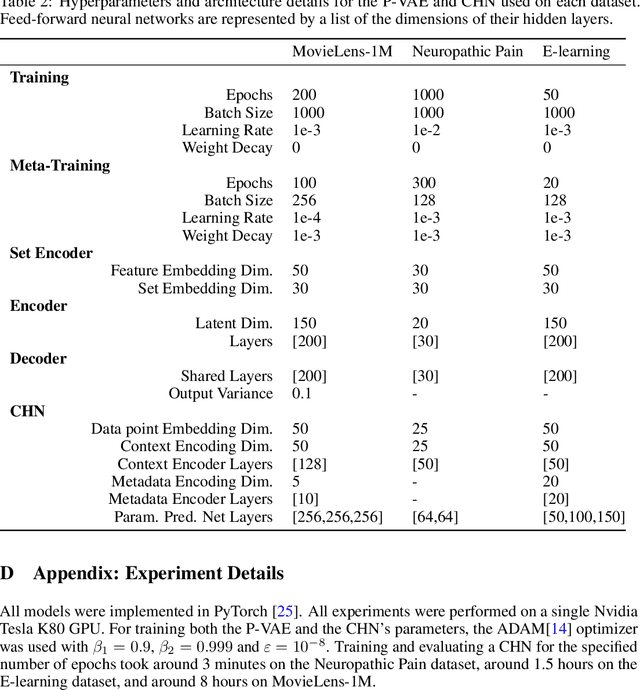
While deep learning has obtained state-of-the-art results in many applications, the adaptation of neural network architectures to incorporate new output features remains a challenge, as neural networks are commonly trained to produce a fixed output dimension. This issue is particularly severe in online learning settings, where new output features, such as items in a recommender system, are added continually with few or no associated observations. As such, methods for adapting neural networks to novel features which are both time and data-efficient are desired. To address this, we propose the Contextual HyperNetwork (CHN), an auxiliary model which generates parameters for extending the base model to a new feature, by utilizing both existing data as well as any observations and/or metadata associated with the new feature. At prediction time, the CHN requires only a single forward pass through a neural network, yielding a significant speed-up when compared to re-training and fine-tuning approaches. To assess the performance of CHNs, we use a CHN to augment a partial variational autoencoder (P-VAE), a deep generative model which can impute the values of missing features in sparsely-observed data. We show that this system obtains improved few-shot learning performance for novel features over existing imputation and meta-learning baselines across recommender systems, e-learning, and healthcare tasks.