 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Learning Systems with First-order Methods
Paper and Code
Apr 12, 2021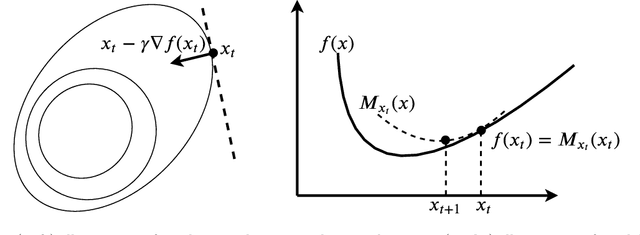

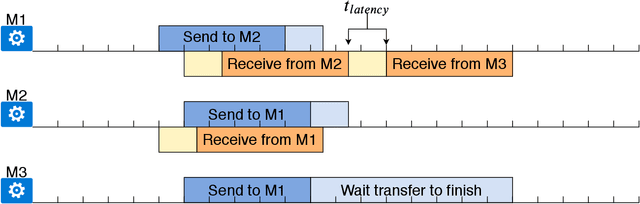
Scalable and efficient distributed learning is one of the main driving forces behind the recent rapid advancement of machine learning and artificial intelligence. One prominent feature of this topic is that recent progresses have been made by researchers in two communities: (1) the system community such as database, data management, and distributed systems, and (2) the machine learning and mathematical optimization community. The interaction and knowledge sharing between these two communities has led to the rapid development of new distributed learning systems and theory. In this work, we hope to provide a brief introduction of some distributed learning techniques that have recently been developed, namely lossy communication compression (e.g., quantization and sparsification), asynchronous communication, and decentralized communication. One special focus in this work is on making sure that it can be easily understood by researchers in both communities -- On the system side, we rely on a simplified system model hiding many system details that are not necessary for the intuition behind the system speedups; while, on the theory side, we rely on minimal assumptions and significantly simplify the proof of some recent work to achieve comparable results.