Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Attention Is All You Need
Paper and Code
Apr 10, 2021
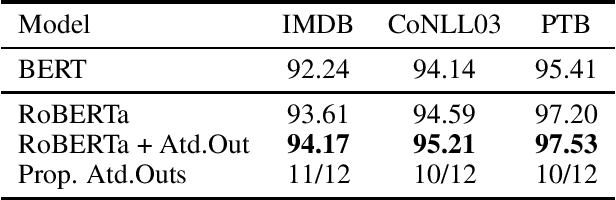
Self-attention based models have achieved remarkable success in natural language processing. However, the self-attention network design is questioned as suboptimal in recent studies, due to its veiled validity and high redundancy. In this paper, we focus on pre-trained language models with self-pruning training design on task-specific tuning. We demonstrate that the lighter state-of-the-art models with nearly 80% of self-attention layers pruned, may achieve even better results on multiple tasks, including natural language understanding, document classification, named entity recognition and POS tagging, with nearly twice faster inference.
View paper on
 OpenReview
OpenReview