 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistically significant detection of semantic shifts using contextual word embeddings
Paper and Code
Apr 08, 2021
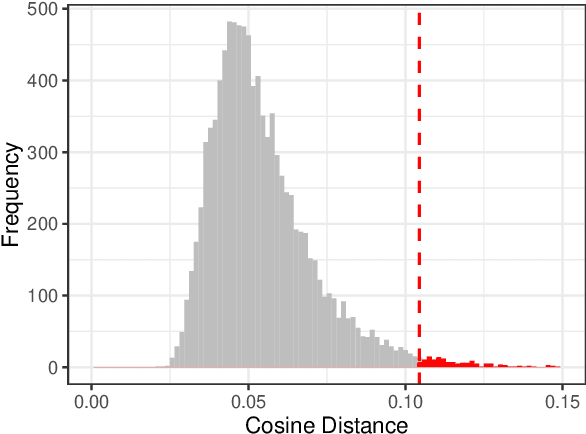
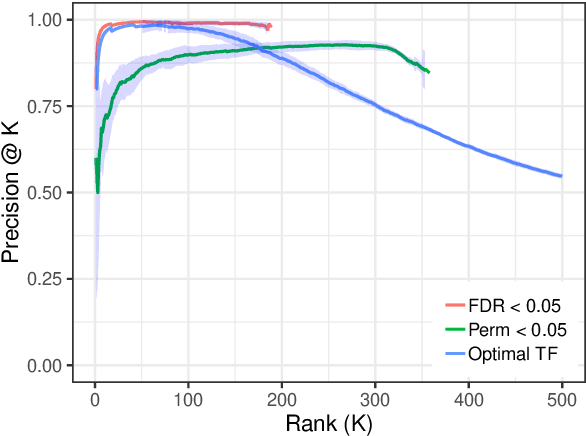

Detecting lexical semantic shifts in smaller data sets, e.g. in historical linguistics and digital humanities, is challenging due to a lack of statistical power. This issue is exacerbated by non-contextual word embeddings that produce one embedding per token and therefore mask the variability present in the data. In this article, we propose an approach to estimate semantic shifts by combining contextual word embeddings with permutation-based statistical tests. Multiple comparisons are addressed using a false discovery rate procedure. We demonstrate the performance of this approach in simulation, achieving consistently high precision by suppressing false positives. We additionally analyzed real-world data from SemEval-2020 Task 1 and the Liverpool FC subreddit corpus. We show that by taking sample variation into account, we can improve the robustness of individual semantic shift estimates without degrading overall performance.