 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Forcing for Machine Translation
Paper and Code
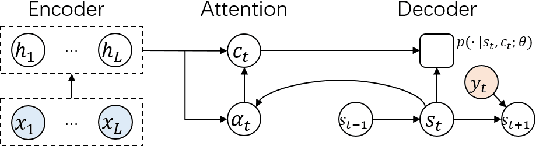
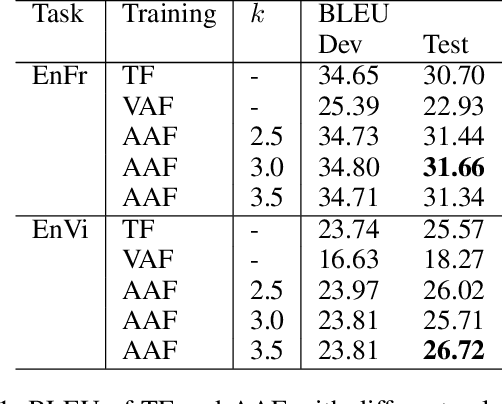
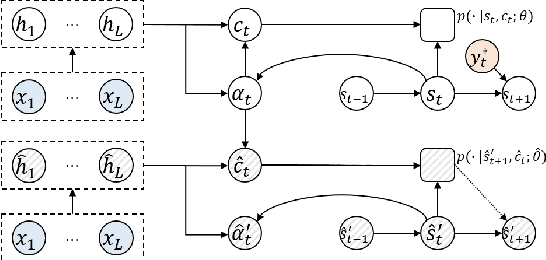
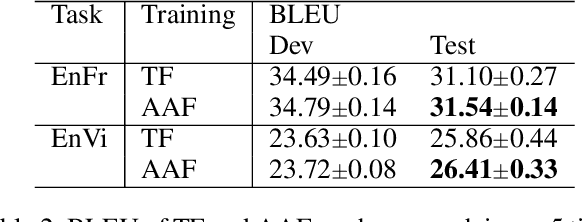
Auto-regressive sequence-to-sequence models with attention mechanisms have achieved state-of-the-art performance in various tasks including Text-To-Speech (TTS) and Neural Machine Translation (NMT). The standard training approach, teacher forcing, guides a model with the reference output history. At inference stage, the generated output history must be used. This mismatch can impact performance. However, it is highly challenging to train the model using the generated output. Several approaches have been proposed to address this problem, normally by selectively using the generated output history. To make training stable, these approaches often require a heuristic schedule or an auxiliary classifier. This paper introduces attention forcing for NMT. This approach guides the model with the generated output history and reference attention, and can reduce the training-inference mismatch without a schedule or a classifier. Attention forcing has been successful in TTS, but its application to NMT is more challenging, due to the discrete and multi-modal nature of the output space. To tackle this problem, this paper adds a selection scheme to vanilla attention forcing, which automatically selects a suitable training approach for each pair of training data. Experiments show that attention forcing can improve the overall translation quality and the diversity of the translations.