 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Acoustic Unit Discovery by Leveraging a Language-Independent Subword Discriminative Feature Representation
Paper and Code
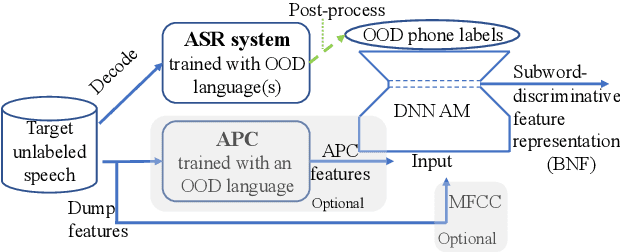
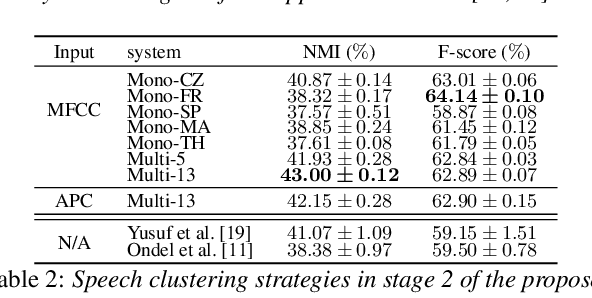
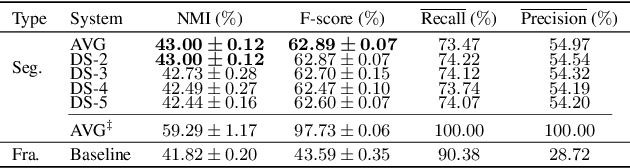
This paper tackles automatically discovering phone-like acoustic units (AUD) from unlabeled speech data. Past studies usually proposed single-step approaches. We propose a two-stage approach: the first stage learns a subword-discriminative feature representation and the second stage applies clustering to the learned representation and obtains phone-like clusters as the discovered acoustic units. In the first stage, a recently proposed method in the task of unsupervised subword modeling is improved by replacing a monolingual out-of-domain (OOD) ASR system with a multilingual one to create a subword-discriminative representation that is more language-independent. In the second stage, segment-level k-means is adopted, and two methods to represent the variable-length speech segments as fixed-dimension feature vectors are compared. Experiments on a very low-resource Mboshi language corpus show that our approach outperforms state-of-the-art AUD in both normalized mutual information (NMI) and F-score. The multilingual ASR improved upon the monolingual ASR in providing OOD phone labels and in estimating the phone boundaries. A comparison of our systems with and without knowing the ground-truth phone boundaries showed a 16% NMI performance gap, suggesting that the current approach can significantly benefit from improved phone boundary estimation.