 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn UMAP's true loss function
Paper and Code


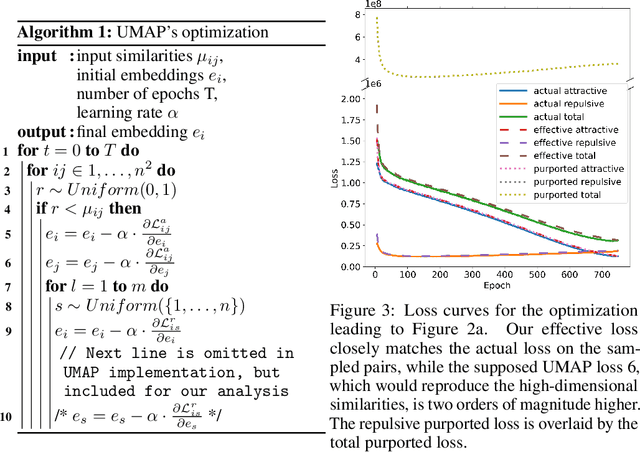
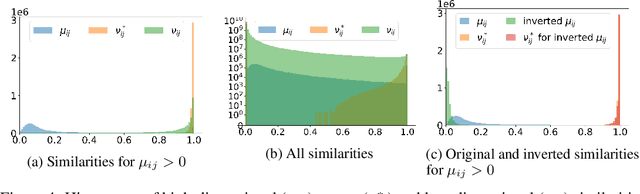
UMAP has supplanted t-SNE as state-of-the-art for visualizing high-dimensional datasets in many disciplines, but the reason for its success is not well understood. In this work, we investigate UMAP's sampling based optimization scheme in detail. We derive UMAP's effective loss function in closed form and find that it differs from the published one. As a consequence, we show that UMAP does not aim to reproduce its theoretically motivated high-dimensional UMAP similarities. Instead, it tries to reproduce similarities that only encode the shared $k$ nearest neighbor graph, thereby challenging the previous understanding of UMAP's effectiveness. Instead, we claim that the key to UMAP's success is its implicit balancing of attraction and repulsion resulting from negative sampling. This balancing in turn facilitates optimization via gradient descent. We corroborate our theoretical findings on toy and single cell RNA sequencing data.