 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Feature Transformations for Discriminative and Generative Continual Learning
Paper and Code

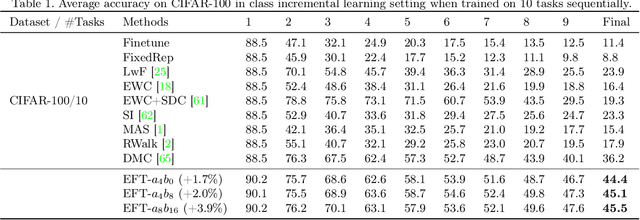
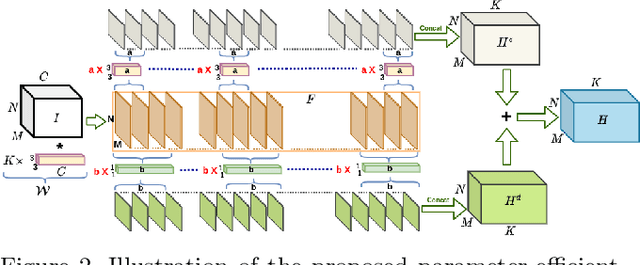
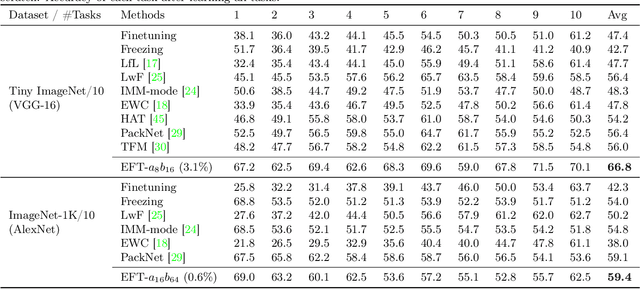
As neural networks are increasingly being applied to real-world applications, mechanisms to address distributional shift and sequential task learning without forgetting are critical. Methods incorporating network expansion have shown promise by naturally adding model capacity for learning new tasks while simultaneously avoiding catastrophic forgetting. However, the growth in the number of additional parameters of many of these types of methods can be computationally expensive at larger scales, at times prohibitively so. Instead, we propose a simple task-specific feature map transformation strategy for continual learning, which we call Efficient Feature Transformations (EFTs). These EFTs provide powerful flexibility for learning new tasks, achieved with minimal parameters added to the base architecture. We further propose a feature distance maximization strategy, which significantly improves task prediction in class incremental settings, without needing expensive generative models. We demonstrate the efficacy and efficiency of our method with an extensive set of experiments in discriminative (CIFAR-100 and ImageNet-1K) and generative (LSUN, CUB-200, Cats) sequences of tasks. Even with low single-digit parameter growth rates, EFTs can outperform many other continual learning methods in a wide range of settings.