 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProof-of-Learning: Definitions and Practice
Paper and Code
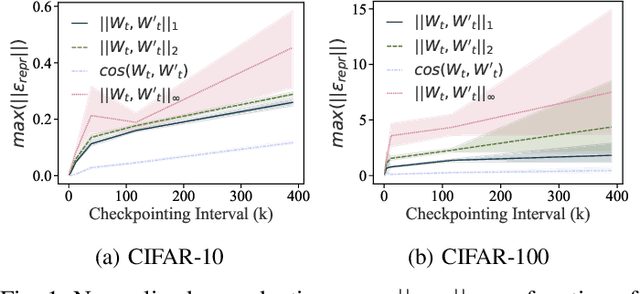
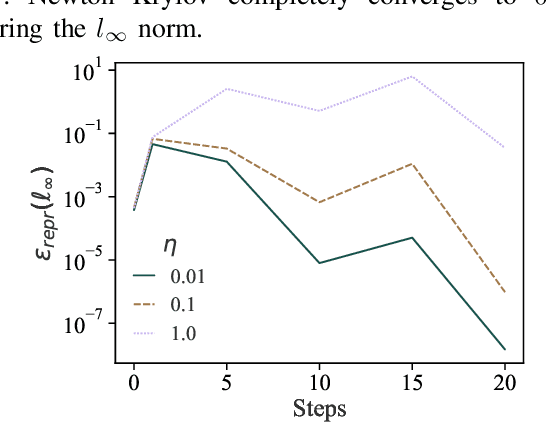
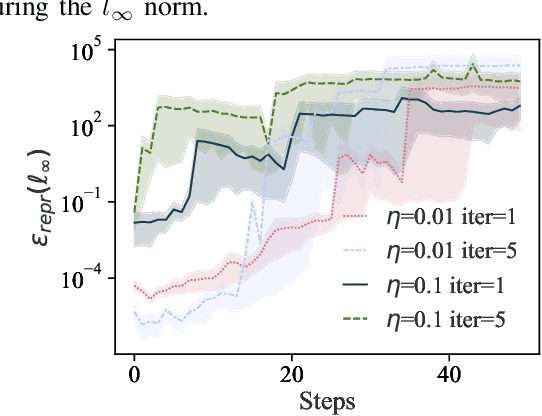
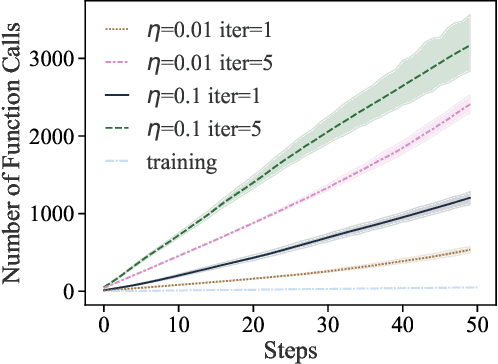
Training machine learning (ML) models typically involves expensive iterative optimization. Once the model's final parameters are released, there is currently no mechanism for the entity which trained the model to prove that these parameters were indeed the result of this optimization procedure. Such a mechanism would support security of ML applications in several ways. For instance, it would simplify ownership resolution when multiple parties contest ownership of a specific model. It would also facilitate the distributed training across untrusted workers where Byzantine workers might otherwise mount a denial-of-service by returning incorrect model updates. In this paper, we remediate this problem by introducing the concept of proof-of-learning in ML. Inspired by research on both proof-of-work and verified computations, we observe how a seminal training algorithm, stochastic gradient descent, accumulates secret information due to its stochasticity. This produces a natural construction for a proof-of-learning which demonstrates that a party has expended the compute require to obtain a set of model parameters correctly. In particular, our analyses and experiments show that an adversary seeking to illegitimately manufacture a proof-of-learning needs to perform *at least* as much work than is needed for gradient descent itself. We also instantiate a concrete proof-of-learning mechanism in both of the scenarios described above. In model ownership resolution, it protects the intellectual property of models released publicly. In distributed training, it preserves availability of the training procedure. Our empirical evaluation validates that our proof-of-learning mechanism is robust to variance induced by the hardware (ML accelerators) and software stacks.