Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating on Incorporating Pretrained and Learnable Speaker Representations for Multi-Speaker Multi-Style Text-to-Speech
Paper and Code
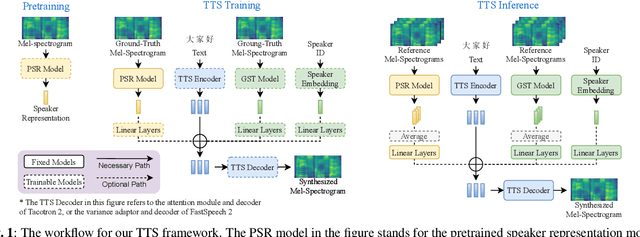
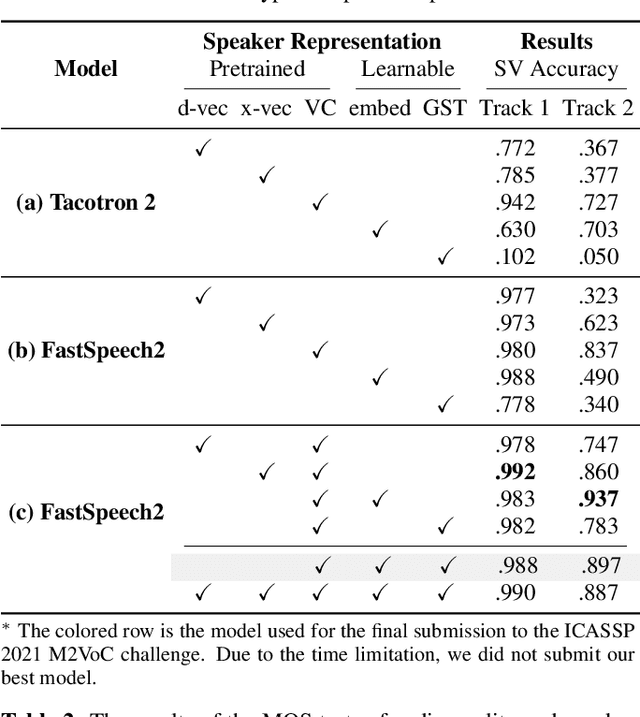
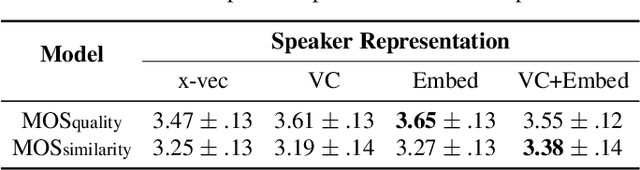

The few-shot multi-speaker multi-style voice cloning task is to synthesize utterances with voice and speaking style similar to a reference speaker given only a few reference samples. In this work, we investigate different speaker representations and proposed to integrate pretrained and learnable speaker representations. Among different types of embeddings, the embedding pretrained by voice conversion achieves the best performance. The FastSpeech 2 model combined with both pretrained and learnable speaker representations shows great generalization ability on few-shot speakers and achieved 2nd place in the one-shot track of the ICASSP 2021 M2VoC challenge.
* Accepted by ICASSP 2021, in the special session of ICASSP 2021 M2VoC
Challenge
View paper on