 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Causal Effect of Data in Class-Incremental Learning
Paper and Code
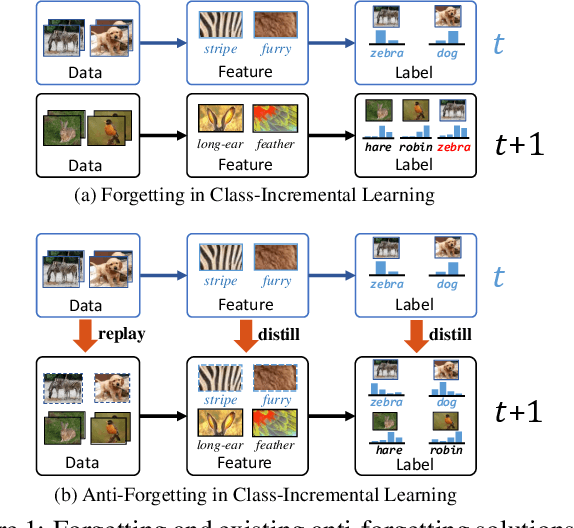
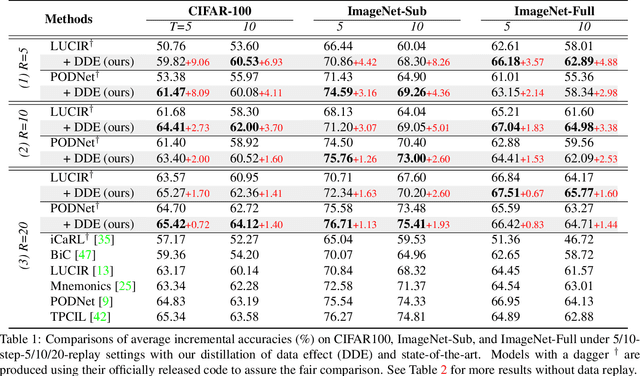
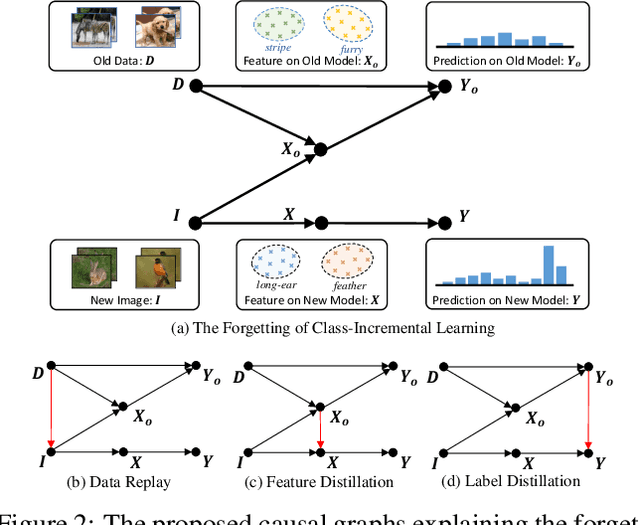
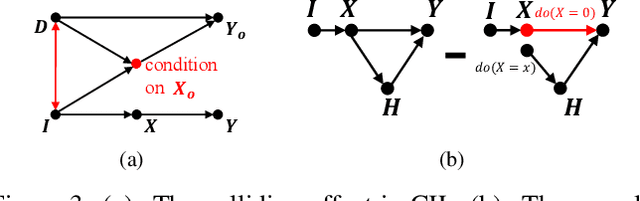
We propose a causal framework to explain the catastrophic forgetting in Class-Incremental Learning (CIL) and then derive a novel distillation method that is orthogonal to the existing anti-forgetting techniques, such as data replay and feature/label distillation. We first 1) place CIL into the framework, 2) answer why the forgetting happens: the causal effect of the old data is lost in new training, and then 3) explain how the existing techniques mitigate it: they bring the causal effect back. Based on the framework, we find that although the feature/label distillation is storage-efficient, its causal effect is not coherent with the end-to-end feature learning merit, which is however preserved by data replay. To this end, we propose to distill the Colliding Effect between the old and the new data, which is fundamentally equivalent to the causal effect of data replay, but without any cost of replay storage. Thanks to the causal effect analysis, we can further capture the Incremental Momentum Effect of the data stream, removing which can help to retain the old effect overwhelmed by the new data effect, and thus alleviate the forgetting of the old class in testing. Extensive experiments on three CIL benchmarks: CIFAR-100, ImageNet-Sub&Full, show that the proposed causal effect distillation can improve various state-of-the-art CIL methods by a large margin (0.72%--9.06%).