 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoftmax Policy Gradient Methods Can Take Exponential Time to Converge
Paper and Code
Feb 22, 2021
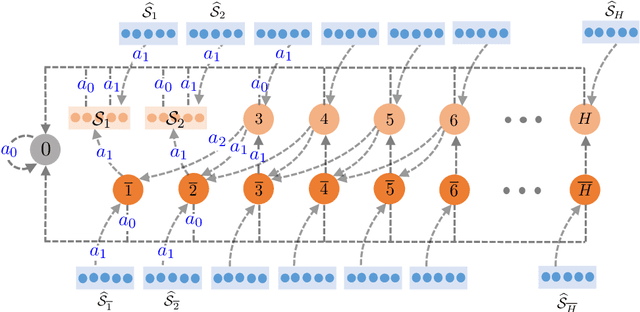
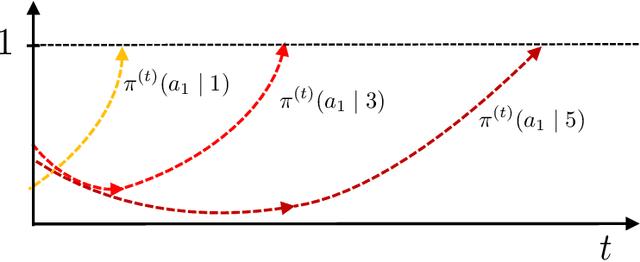
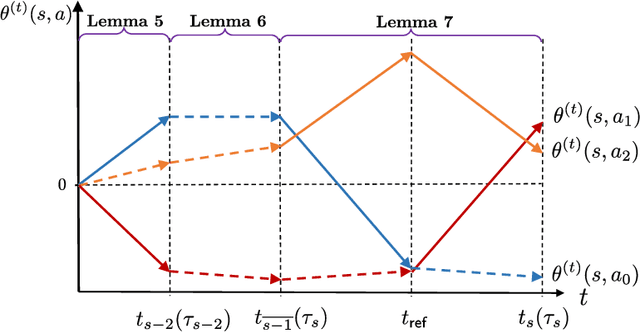
The softmax policy gradient (PG) method, which performs gradient ascent under softmax policy parameterization, is arguably one of the de facto implementations of policy optimization in modern reinforcement learning. For $\gamma$-discounted infinite-horizon tabular Markov decision processes (MDPs), remarkable progress has recently been achieved towards establishing global convergence of softmax PG methods in finding a near-optimal policy. However, prior results fall short of delineating clear dependencies of convergence rates on salient parameters such as the cardinality of the state space $\mathcal{S}$ and the effective horizon $\frac{1}{1-\gamma}$, both of which could be excessively large. In this paper, we deliver a pessimistic message regarding the iteration complexity of softmax PG methods, despite assuming access to exact gradient computation. Specifically, we demonstrate that softmax PG methods can take exponential time -- in terms of $|\mathcal{S}|$ and $\frac{1}{1-\gamma}$ -- to converge, even in the presence of a benign policy initialization and an initial state distribution amenable to exploration. This is accomplished by characterizing the algorithmic dynamics over a carefully-constructed MDP containing only three actions. Our exponential lower bound hints at the necessity of carefully adjusting update rules or enforcing proper regularization in accelerating PG methods.