 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Convex Optimization with Spectral Radius Regularization
Paper and Code

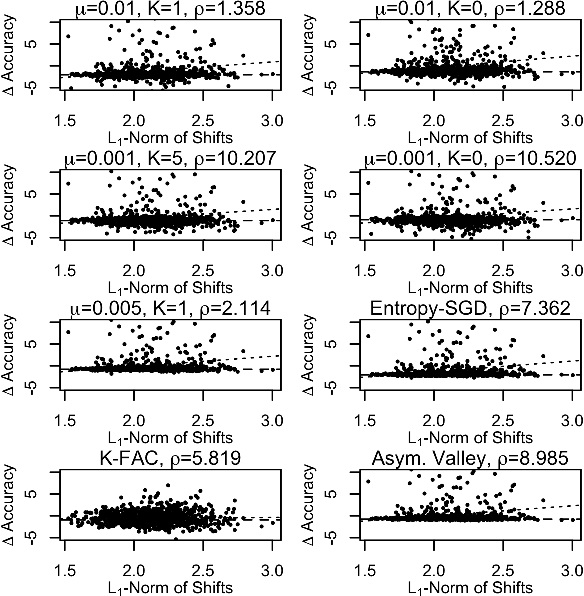
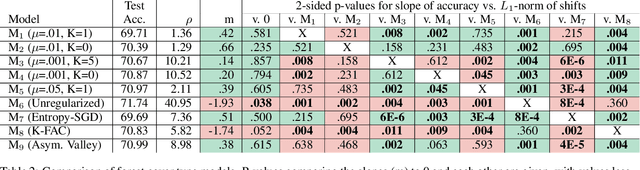
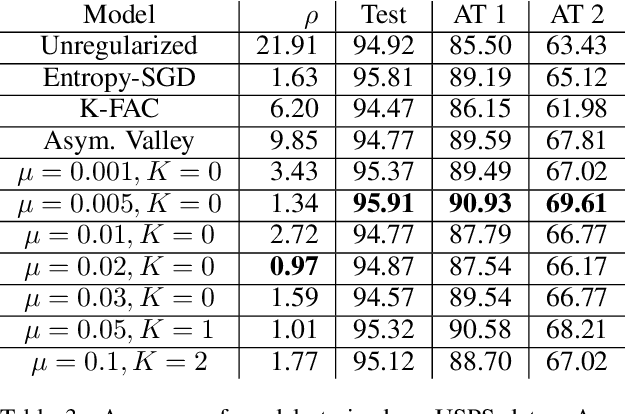
We develop a regularization method which finds flat minima during the training of deep neural networks and other machine learning models. These minima generalize better than sharp minima, allowing models to better generalize to real word test data, which may be distributed differently from the training data. Specifically, we propose a method of regularized optimization to reduce the spectral radius of the Hessian of the loss function. Additionally, we derive algorithms to efficiently perform this optimization on neural networks and prove convergence results for these algorithms. Furthermore, we demonstrate that our algorithm works effectively on multiple real world applications in multiple domains including healthcare. In order to show our models generalize well, we introduce different methods of testing generalizability.