 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generic Descent Aggregation Framework for Gradient-based Bi-level Optimization
Paper and Code

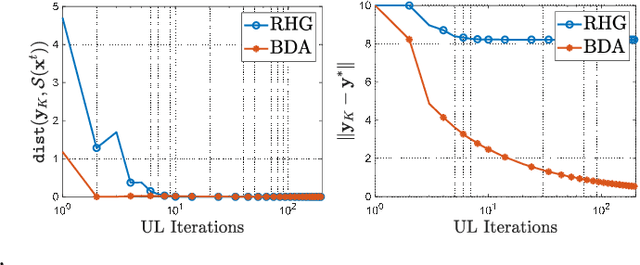
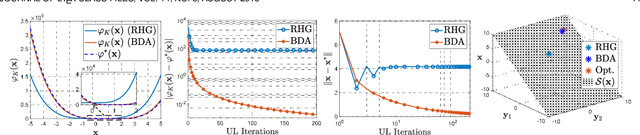
In recent years, gradient-based methods for solving bi-level optimization tasks have drawn a great deal of interest from the machine learning community. However, to calculate the gradient of the best response, existing research always relies on the singleton of the lower-level solution set (a.k.a., Lower-Level Singleton, LLS). In this work, by formulating bi-level models from an optimistic bi-level viewpoint, we first establish a novel Bi-level Descent Aggregation (BDA) framework, which aggregates hierarchical objectives of both upper level and lower level. The flexibility of our framework benefits from the embedded replaceable task-tailored iteration dynamics modules, thereby capturing a wide range of bi-level learning tasks. Theoretically, we derive a new methodology to prove the convergence of BDA framework without the LLS restriction. Besides, the new proof recipe we propose is also engaged to improve the convergence results of conventional gradient-based bi-level methods under the LLS simplification. Furthermore, we employ a one-stage technique to accelerate the back-propagation calculation in a numerical manner. Extensive experiments justify our theoretical results and demonstrate the superiority of the proposed algorithm for hyper-parameter optimization and meta-learning tasks.