 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Recursive Belief States in Multi-Agent Reinforcement Learning
Paper and Code
Feb 03, 2021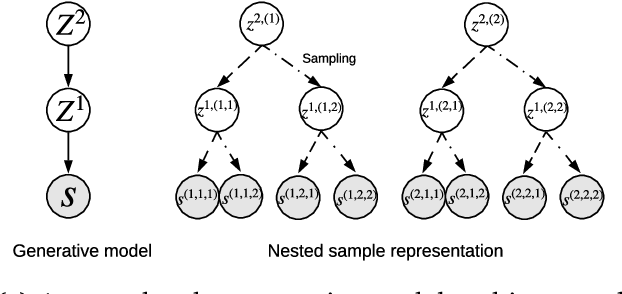
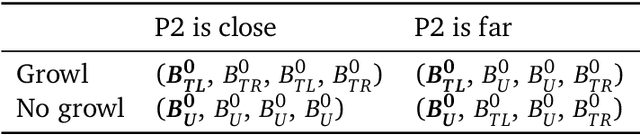
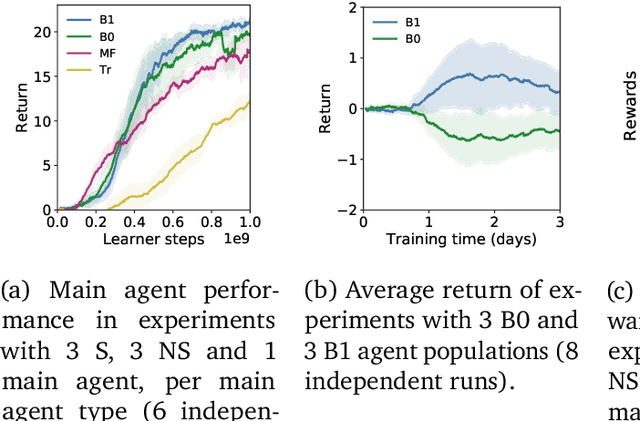
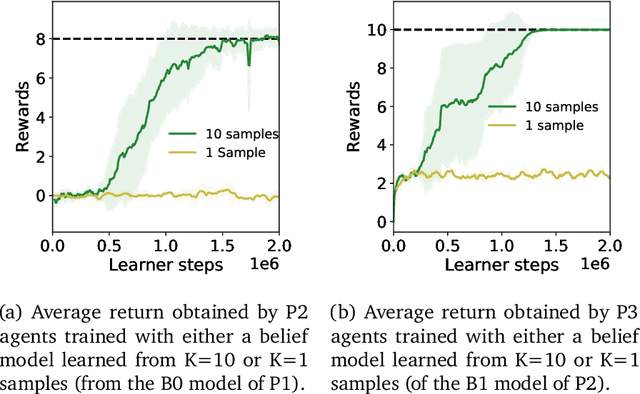
In multi-agent reinforcement learning, the problem of learning to act is particularly difficult because the policies of co-players may be heavily conditioned on information only observed by them. On the other hand, humans readily form beliefs about the knowledge possessed by their peers and leverage beliefs to inform decision-making. Such abilities underlie individual success in a wide range of Markov games, from bluffing in Poker to conditional cooperation in the Prisoner's Dilemma, to convention-building in Bridge. Classical methods are usually not applicable to complex domains due to the intractable nature of hierarchical beliefs (i.e. beliefs of other agents' beliefs). We propose a scalable method to approximate these belief structures using recursive deep generative models, and to use the belief models to obtain representations useful to acting in complex tasks. Our agents trained with belief models outperform model-free baselines with equivalent representational capacity using common training paradigms. We also show that higher-order belief models outperform agents with lower-order models.