 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLiMP: A Benchmark for Chinese Language Model Evaluation
Paper and Code
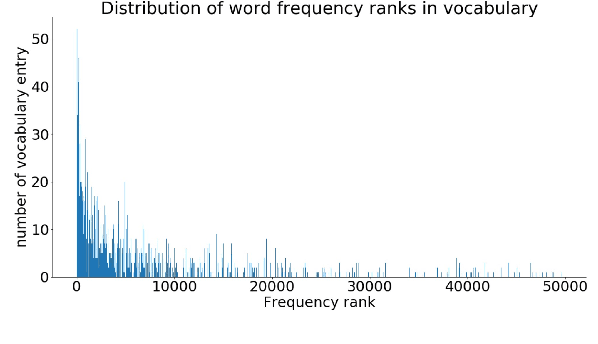
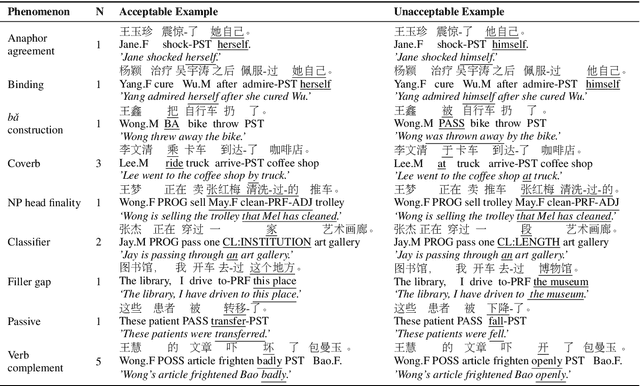
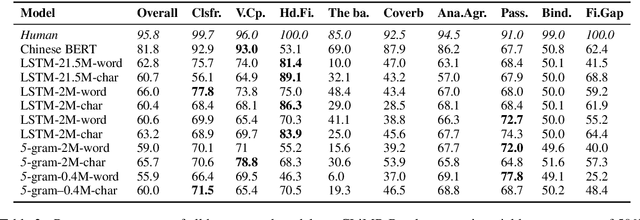
Linguistically informed analyses of language models (LMs) contribute to the understanding and improvement of these models. Here, we introduce the corpus of Chinese linguistic minimal pairs (CLiMP), which can be used to investigate what knowledge Chinese LMs acquire. CLiMP consists of sets of 1,000 minimal pairs (MPs) for 16 syntactic contrasts in Mandarin, covering 9 major Mandarin linguistic phenomena. The MPs are semi-automatically generated, and human agreement with the labels in CLiMP is 95.8%. We evaluated 11 different LMs on CLiMP, covering n-grams, LSTMs, and Chinese BERT. We find that classifier-noun agreement and verb complement selection are the phenomena that models generally perform best at. However, models struggle the most with the ba construction, binding, and filler-gap dependencies. Overall, Chinese BERT achieves an 81.8% average accuracy, while the performances of LSTMs and 5-grams are only moderately above chance level.