 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Multilingual Pre-trained Language Model with Byte-level Subwords
Paper and Code
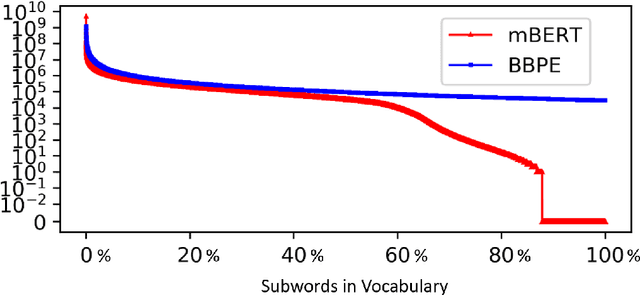
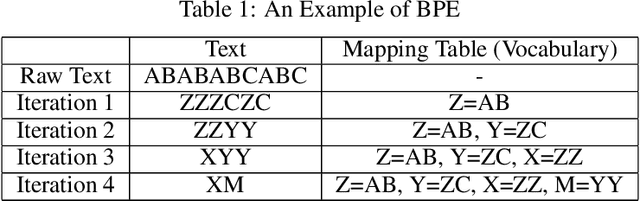

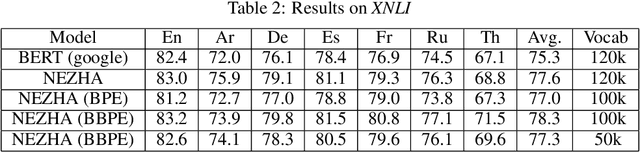
The pre-trained language models have achieved great successes in various natural language understanding (NLU) tasks due to its capacity to capture the deep contextualized information in text by pre-training on large-scale corpora. One of the fundamental components in pre-trained language models is the vocabulary, especially for training multilingual models on many different languages. In the technical report, we present our practices on training multilingual pre-trained language models with BBPE: Byte-Level BPE (i.e., Byte Pair Encoding). In the experiment, we adopted the architecture of NEZHA as the underlying pre-trained language model and the results show that NEZHA trained with byte-level subwords consistently outperforms Google multilingual BERT and vanilla NEZHA by a notable margin in several multilingual NLU tasks. We release the source code of our byte-level vocabulary building tools and the multilingual pre-trained language models.