 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-Supervised Hierarchical Models for Predicting Persuasive Strategies in Good-faith Textual Requests
Paper and Code
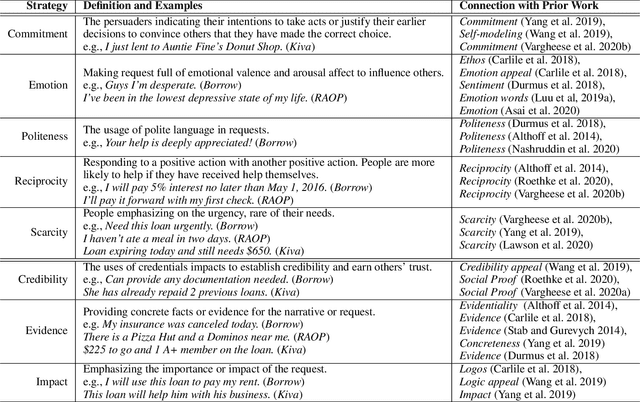
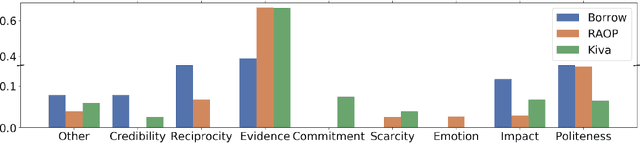

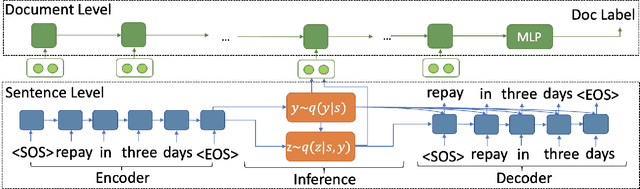
Modeling persuasive language has the potential to better facilitate our decision-making processes. Despite its importance, computational modeling of persuasion is still in its infancy, largely due to the lack of benchmark datasets that can provide quantitative labels of persuasive strategies to expedite this line of research. To this end, we introduce a large-scale multi-domain text corpus for modeling persuasive strategies in good-faith text requests. Moreover, we design a hierarchical weakly-supervised latent variable model that can leverage partially labeled data to predict such associated persuasive strategies for each sentence, where the supervision comes from both the overall document-level labels and very limited sentence-level labels. Experimental results showed that our proposed method outperformed existing semi-supervised baselines significantly. We have publicly released our code at https://github.com/GT-SALT/Persuasion_Strategy_WVAE.