 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Object-Level Visual Context Modeling for Multimodal Machine Translation: Masking Irrelevant Objects Helps Grounding
Paper and Code

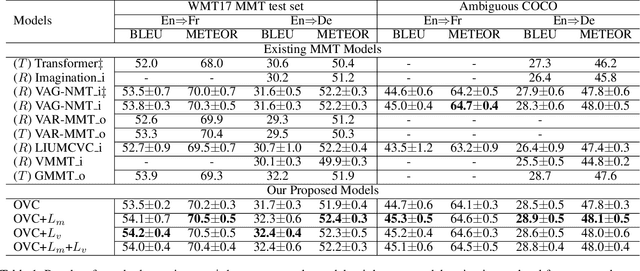
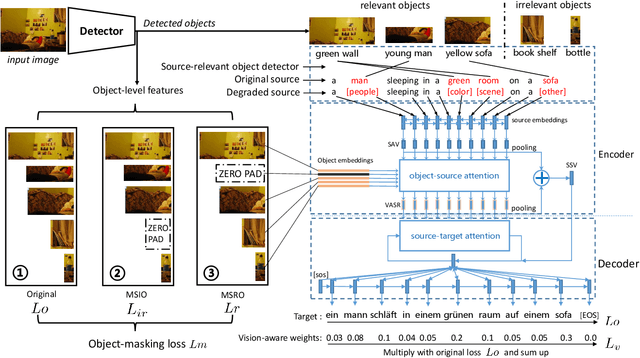
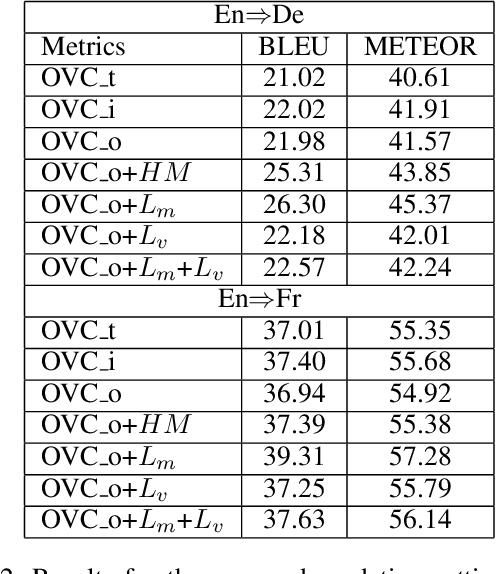
Visual context provides grounding information for multimodal machine translation (MMT). However, previous MMT models and probing studies on visual features suggest that visual information is less explored in MMT as it is often redundant to textual information. In this paper, we propose an object-level visual context modeling framework (OVC) to efficiently capture and explore visual information for multimodal machine translation. With detected objects, the proposed OVC encourages MMT to ground translation on desirable visual objects by masking irrelevant objects in the visual modality. We equip the proposed with an additional object-masking loss to achieve this goal. The object-masking loss is estimated according to the similarity between masked objects and the source texts so as to encourage masking source-irrelevant objects. Additionally, in order to generate vision-consistent target words, we further propose a vision-weighted translation loss for OVC. Experiments on MMT datasets demonstrate that the proposed OVC model outperforms state-of-the-art MMT models and analyses show that masking irrelevant objects helps grounding in MMT.