 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Representation Meta-Reinforcement Learning for Instant Adaptation
Paper and Code
Jan 12, 2021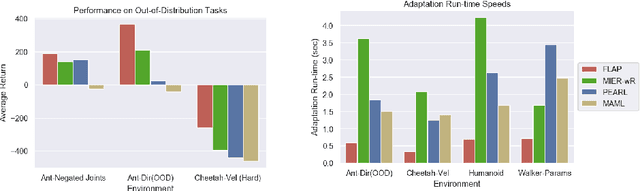
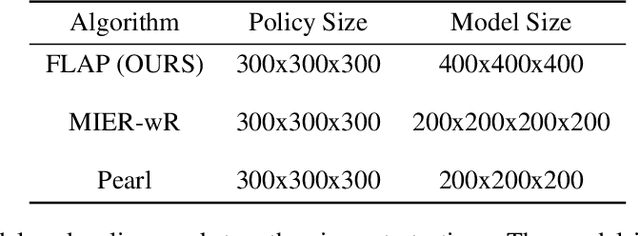
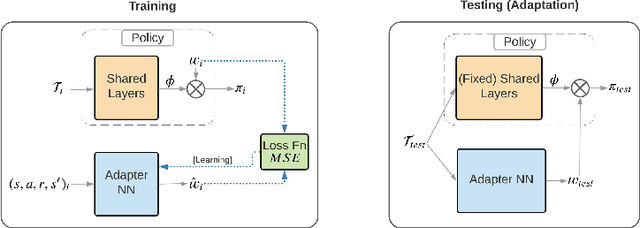
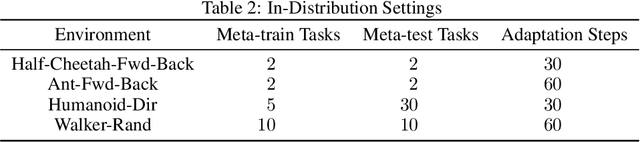
This paper introduces Fast Linearized Adaptive Policy (FLAP), a new meta-reinforcement learning (meta-RL) method that is able to extrapolate well to out-of-distribution tasks without the need to reuse data from training, and adapt almost instantaneously with the need of only a few samples during testing. FLAP builds upon the idea of learning a shared linear representation of the policy so that when adapting to a new task, it suffices to predict a set of linear weights. A separate adapter network is trained simultaneously with the policy such that during adaptation, we can directly use the adapter network to predict these linear weights instead of updating a meta-policy via gradient descent, such as in prior meta-RL methods like MAML, to obtain the new policy. The application of the separate feed-forward network not only speeds up the adaptation run-time significantly, but also generalizes extremely well to very different tasks that prior Meta-RL methods fail to generalize to. Experiments on standard continuous-control meta-RL benchmarks show FLAP presenting significantly stronger performance on out-of-distribution tasks with up to double the average return and up to 8X faster adaptation run-time speeds when compared to prior methods.