 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdam revisited: a weighted past gradients perspective
Paper and Code
Jan 01, 2021
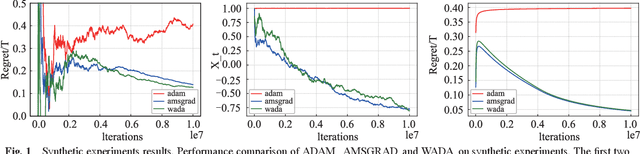
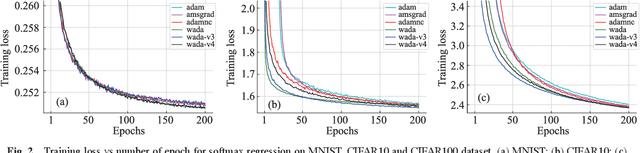
Adaptive learning rate methods have been successfully applied in many fields, especially in training deep neural networks. Recent results have shown that adaptive methods with exponential increasing weights on squared past gradients (i.e., ADAM, RMSPROP) may fail to converge to the optimal solution. Though many algorithms, such as AMSGRAD and ADAMNC, have been proposed to fix the non-convergence issues, achieving a data-dependent regret bound similar to or better than ADAGRAD is still a challenge to these methods. In this paper, we propose a novel adaptive method weighted adaptive algorithm (WADA) to tackle the non-convergence issues. Unlike AMSGRAD and ADAMNC, we consider using a milder growing weighting strategy on squared past gradient, in which weights grow linearly. Based on this idea, we propose weighted adaptive gradient method framework (WAGMF) and implement WADA algorithm on this framework. Moreover, we prove that WADA can achieve a weighted data-dependent regret bound, which could be better than the original regret bound of ADAGRAD when the gradients decrease rapidly. This bound may partially explain the good performance of ADAM in practice. Finally, extensive experiments demonstrate the effectiveness of WADA and its variants in comparison with several variants of ADAM on training convex problems and deep neural networks.