 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Monocular Depth Reconstruction of Non-Rigid Scenes
Paper and Code
Dec 31, 2020
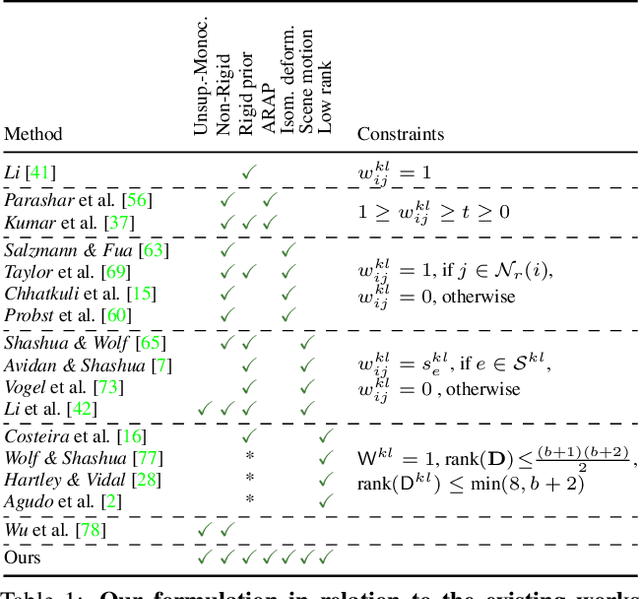
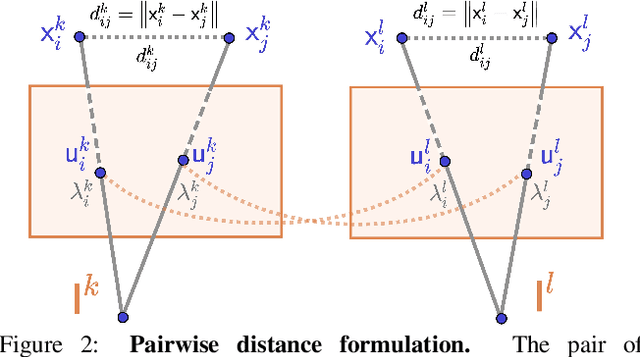
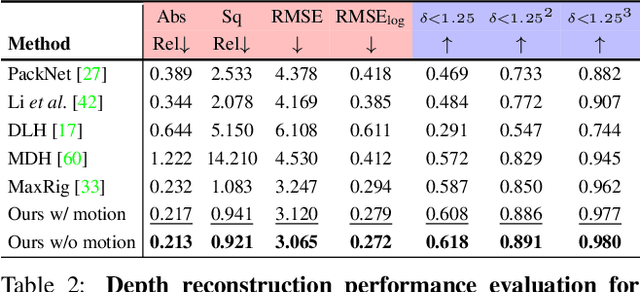
Monocular depth reconstruction of complex and dynamic scenes is a highly challenging problem. While for rigid scenes learning-based methods have been offering promising results even in unsupervised cases, there exists little to no literature addressing the same for dynamic and deformable scenes. In this work, we present an unsupervised monocular framework for dense depth estimation of dynamic scenes, which jointly reconstructs rigid and non-rigid parts without explicitly modelling the camera motion. Using dense correspondences, we derive a training objective that aims to opportunistically preserve pairwise distances between reconstructed 3D points. In this process, the dense depth map is learned implicitly using the as-rigid-as-possible hypothesis. Our method provides promising results, demonstrating its capability of reconstructing 3D from challenging videos of non-rigid scenes. Furthermore, the proposed method also provides unsupervised motion segmentation results as an auxiliary output.