 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefine and Imitate: Reducing Repetition and Inconsistency in Persuasion Dialogues via Reinforcement Learning and Human Demonstration
Paper and Code
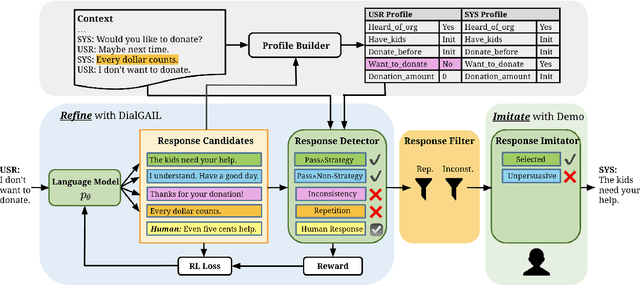
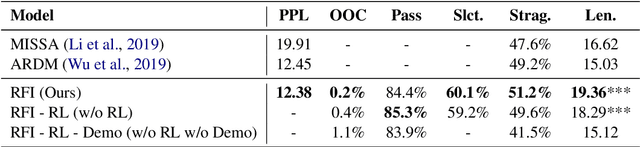
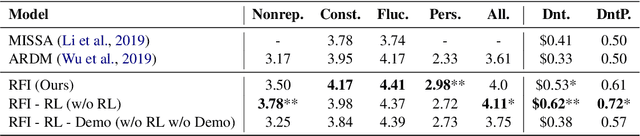
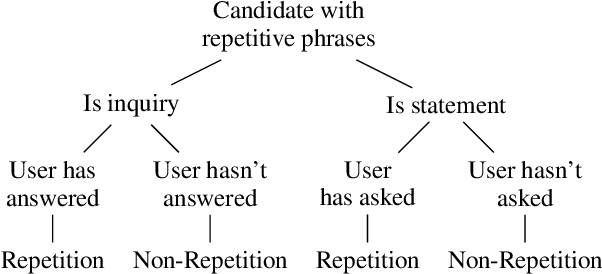
Despite the recent success of large-scale language models on various downstream NLP tasks, the repetition and inconsistency problems still persist in dialogue response generation. Previous approaches have attempted to avoid repetition by penalizing the language model's undesirable behaviors in the loss function. However, these methods focus on token-level information and can lead to incoherent responses and uninterpretable behaviors. To alleviate these issues, we propose to apply reinforcement learning to refine an MLE-based language model without user simulators, and distill sentence-level information about repetition, inconsistency and task relevance through rewards. In addition, to better accomplish the dialogue task, the model learns from human demonstration to imitate intellectual activities such as persuasion, and selects the most persuasive responses. Experiments show that our model outperforms previous state-of-the-art dialogue models on both automatic metrics and human evaluation results on a donation persuasion task, and generates more diverse, consistent and persuasive conversations according to the user feedback.