 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLTrust: Byzantine-robust Federated Learning via Trust Bootstrapping
Paper and Code
Dec 27, 2020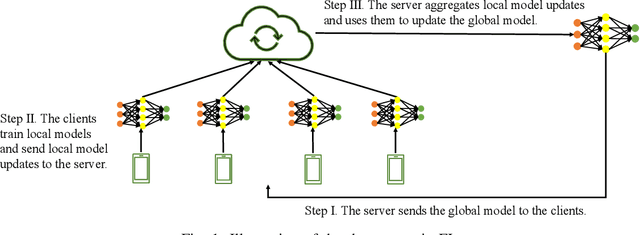
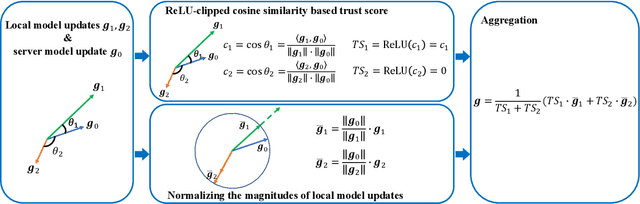
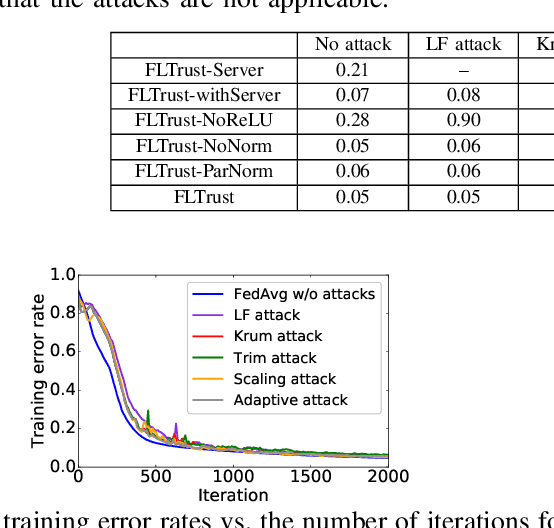
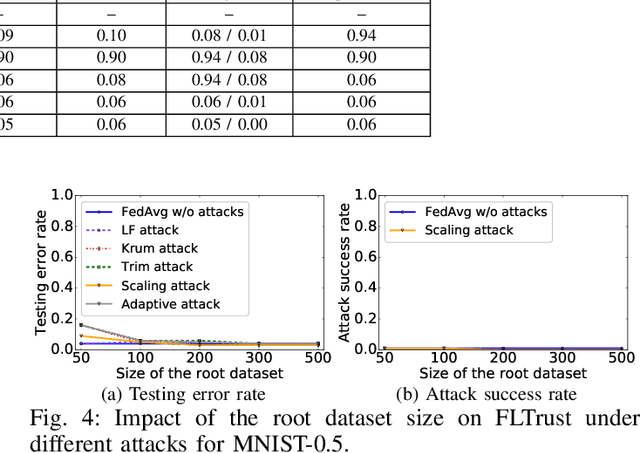
Byzantine-robust federated learning aims to enable a service provider to learn an accurate global model when a bounded number of clients are malicious. The key idea of existing Byzantine-robust federated learning methods is that the service provider performs statistical analysis among the clients' local model updates and removes suspicious ones, before aggregating them to update the global model. However, malicious clients can still corrupt the global models in these methods via sending carefully crafted local model updates to the service provider. The fundamental reason is that there is no root of trust in existing federated learning methods. In this work, we bridge the gap via proposing FLTrust, a new federated learning method in which the service provider itself bootstraps trust. In particular, the service provider itself collects a clean small training dataset (called root dataset) for the learning task and the service provider maintains a model (called server model) based on it to bootstrap trust. In each iteration, the service provider first assigns a trust score to each local model update from the clients, where a local model update has a lower trust score if its direction deviates more from the direction of the server model update. Then, the service provider normalizes the magnitudes of the local model updates such that they lie in the same hyper-sphere as the server model update in the vector space. Our normalization limits the impact of malicious local model updates with large magnitudes. Finally, the service provider computes the average of the normalized local model updates weighted by their trust scores as a global model update, which is used to update the global model. Our extensive evaluations on six datasets from different domains show that our FLTrust is secure against both existing attacks and strong adaptive attacks.