 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariable-Shot Adaptation for Online Meta-Learning
Paper and Code
Dec 14, 2020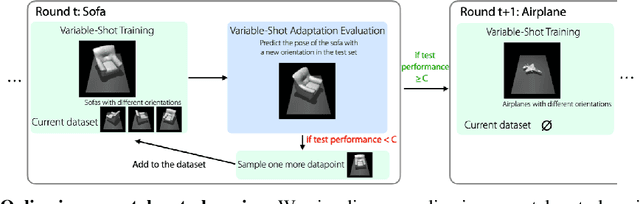
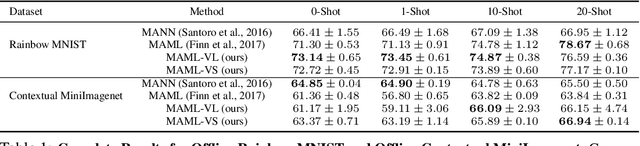


Few-shot meta-learning methods consider the problem of learning new tasks from a small, fixed number of examples, by meta-learning across static data from a set of previous tasks. However, in many real world settings, it is more natural to view the problem as one of minimizing the total amount of supervision --- both the number of examples needed to learn a new task and the amount of data needed for meta-learning. Such a formulation can be studied in a sequential learning setting, where tasks are presented in sequence. When studying meta-learning in this online setting, a critical question arises: can meta-learning improve over the sample complexity and regret of standard empirical risk minimization methods, when considering both meta-training and adaptation together? The answer is particularly non-obvious for meta-learning algorithms with complex bi-level optimizations that may demand large amounts of meta-training data. To answer this question, we extend previous meta-learning algorithms to handle the variable-shot settings that naturally arise in sequential learning: from many-shot learning at the start, to zero-shot learning towards the end. On sequential learning problems, we find that meta-learning solves the full task set with fewer overall labels and achieves greater cumulative performance, compared to standard supervised methods. These results suggest that meta-learning is an important ingredient for building learning systems that continuously learn and improve over a sequence of problems.