 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParsiNLU: A Suite of Language Understanding Challenges for Persian
Paper and Code

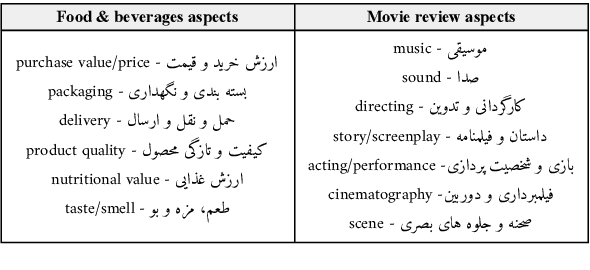
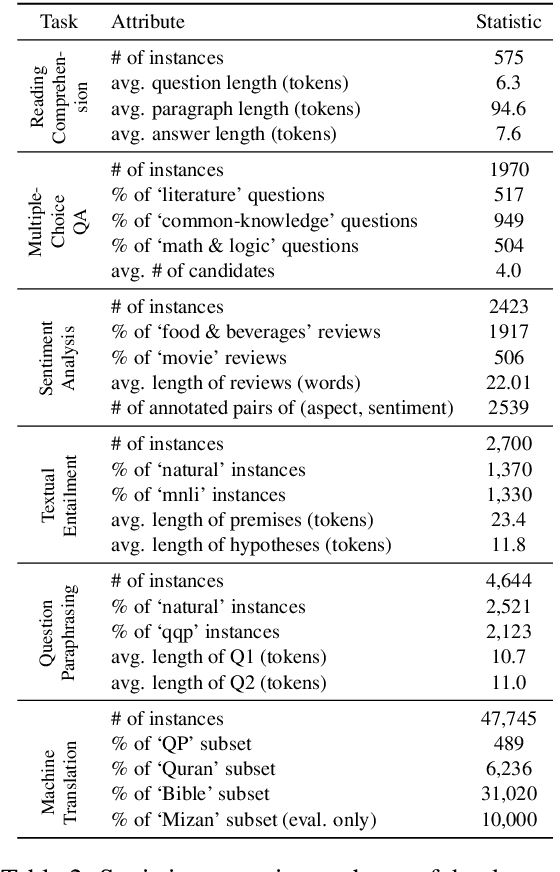
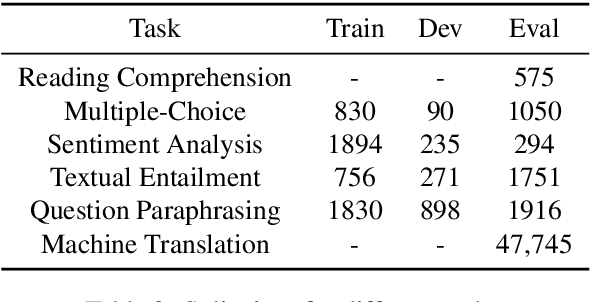
Despite the progress made in recent years in addressing natural language understanding (NLU) challenges, the majority of this progress remains to be concentrated on resource-rich languages like English. This work focuses on Persian language, one of the widely spoken languages in the world, and yet there are few NLU datasets available for this rich language. The availability of high-quality evaluation datasets is a necessity for reliable assessment of the progress on different NLU tasks and domains. We introduce ParsiNLU, the first benchmark in Persian language that includes a range of high-level tasks -- Reading Comprehension, Textual Entailment, etc. These datasets are collected in a multitude of ways, often involving manual annotations by native speakers. This results in over 14.5$k$ new instances across 6 distinct NLU tasks. Besides, we present the first results on state-of-the-art monolingual and multi-lingual pre-trained language-models on this benchmark and compare them with human performance, which provides valuable insights into our ability to tackle natural language understanding challenges in Persian. We hope ParsiNLU fosters further research and advances in Persian language understanding.