 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecuring Deep Spiking Neural Networks against Adversarial Attacks through Inherent Structural Parameters
Paper and Code
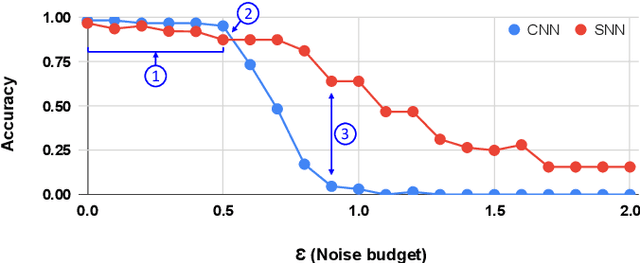
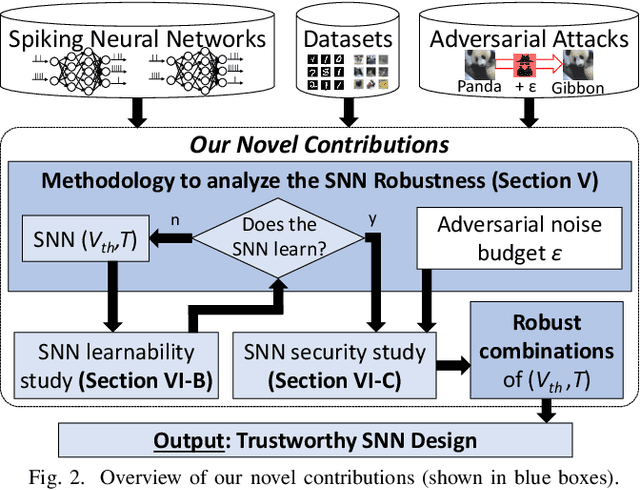
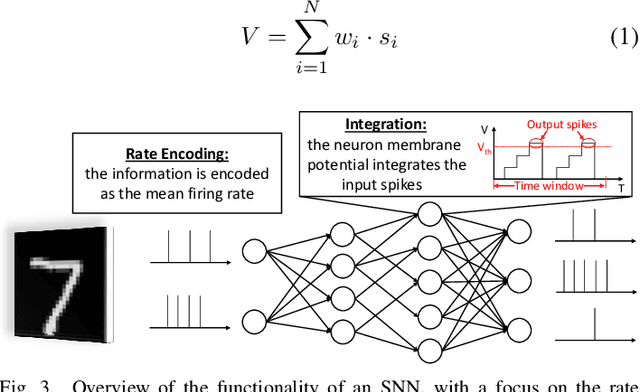
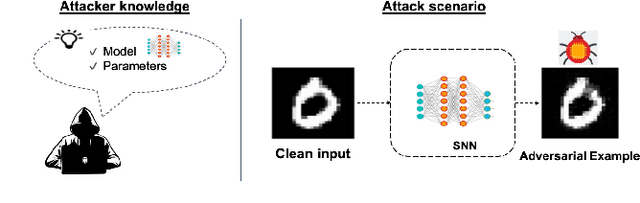
Deep Learning (DL) algorithms have gained popularity owing to their practical problem-solving capacity. However, they suffer from a serious integrity threat, i.e., their vulnerability to adversarial attacks. In the quest for DL trustworthiness, recent works claimed the inherent robustness of Spiking Neural Networks (SNNs) to these attacks, without considering the variability in their structural spiking parameters. This paper explores the security enhancement of SNNs through internal structural parameters. Specifically, we investigate the SNNs robustness to adversarial attacks with different values of the neuron's firing voltage thresholds and time window boundaries. We thoroughly study SNNs security under different adversarial attacks in the strong white-box setting, with different noise budgets and under variable spiking parameters. Our results show a significant impact of the structural parameters on the SNNs' security, and promising sweet spots can be reached to design trustworthy SNNs with 85% higher robustness than a traditional non-spiking DL system. To the best of our knowledge, this is the first work that investigates the impact of structural parameters on SNNs robustness to adversarial attacks. The proposed contributions and the experimental framework is available online to the community for reproducible research.