 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence-aware Non-repetitive Multimodal Transformers for TextCaps
Paper and Code
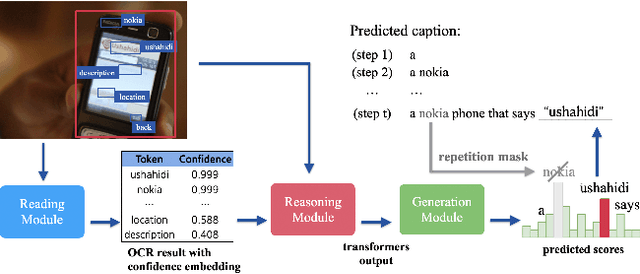
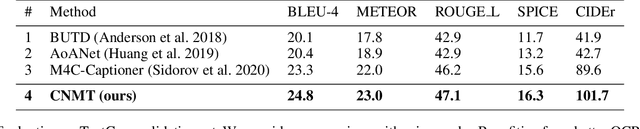
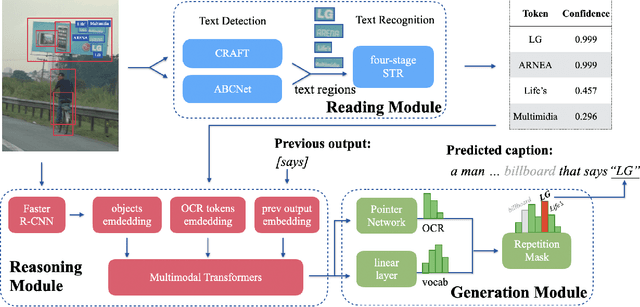
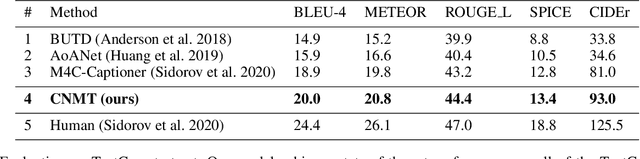
When describing an image, reading text in the visual scene is crucial to understand the key information. Recent work explores the TextCaps task, i.e. image captioning with reading Optical Character Recognition (OCR) tokens, which requires models to read text and cover them in generated captions. Existing approaches fail to generate accurate descriptions because of their (1) poor reading ability; (2) inability to choose the crucial words among all extracted OCR tokens; (3) repetition of words in predicted captions. To this end, we propose a Confidence-aware Non-repetitive Multimodal Transformers (CNMT) to tackle the above challenges. Our CNMT consists of a reading, a reasoning and a generation modules, in which Reading Module employs better OCR systems to enhance text reading ability and a confidence embedding to select the most noteworthy tokens. To address the issue of word redundancy in captions, our Generation Module includes a repetition mask to avoid predicting repeated word in captions. Our model outperforms state-of-the-art models on TextCaps dataset, improving from 81.0 to 93.0 in CIDEr. Our source code is publicly available.